不同程序在运行时有各种各样的内存访问足迹,masim工具可以生成你想要的内存访问足迹,方便分析一些内存观测数据的准确性。
masim工具来自于仓库:sjp38/masim: memory access workload simulator 从config文件夹里可以看出,配置主要分为两大模块:regions定义后续用到的内存区域,每个phase有一个运行时间也可以取一个名字,然后以设置读/写模式去随机/顺序访问之前定义的区域。然后查看./masim --help找到合适的运行方式。
masim.h 中主要的四个结构体
- mregion 内存区域
- rw_mode 访问模式(只读、只写、读写混合)
- access 访问模式
- phase 模拟阶段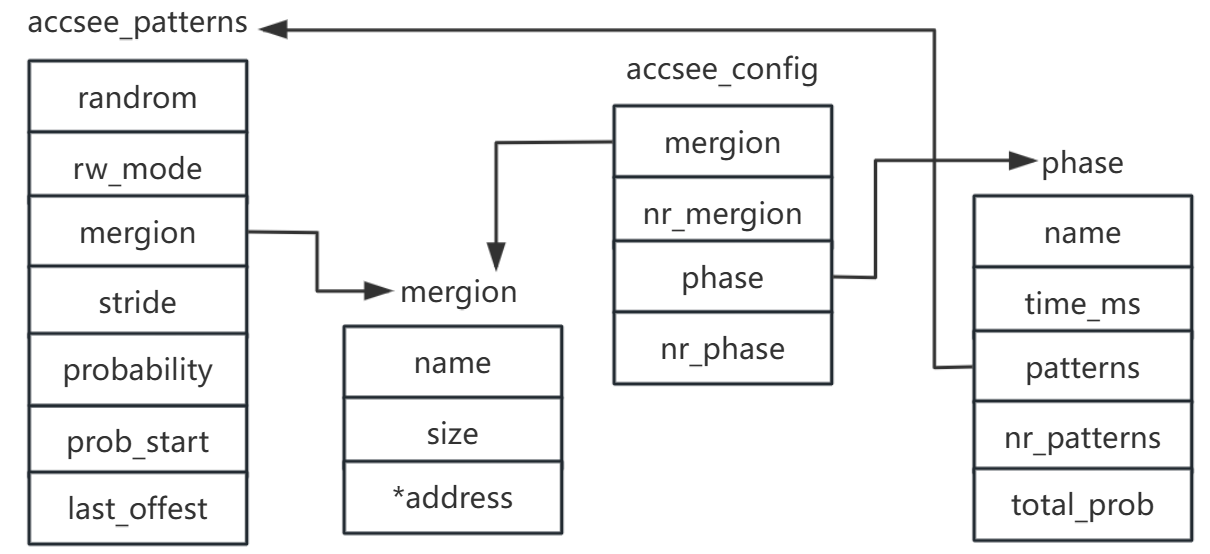
动态缓冲区
misc.h
struct dynbuf {
void *buf; // 指向缓冲区的指针
size_t len; // 缓冲区当前长度
size_t cap; // 缓冲区容量
size_t grow_step; // 缓冲区每次增长的步长?!
size_t head; // 缓冲区头部位置
};
misc.c
void *dbuf_at(struct dynbuf *dbuf, size_t offset) // 返回动态缓冲区中从 buf 开始偏移 offset 字节的位置
void *dbuf_buf(struct dynbuf *dbuf) // 返回缓冲区的起始地址,即 buf
char *dbuf_str(struct dynbuf *dbuf) // 返回缓冲区起始地址,并将其转换为 char * 类型。
char *dbuf_free_str(struct dynbuf *dbuf) // 释放动态缓冲区结构体内存, 返回缓冲区起始地址字符串
size_t dbuf_len(struct dynbuf *dbuf) // 返回当前缓冲区的长度
int dbuf_set_head(struct dynbuf *dbuf, size_t offset) // 设置缓冲区的头部位置为 offset
size_t dbuf_read(struct dynbuf *dbuf, void *buf, size_t sz) // 从缓冲区读取 sz 字节到 buf 中;读取成功后,更新缓冲区的头部位置。
void dbuf_append(struct dynbuf *dbuf, void *bytes, size_t sz) // 将 sz 字节的数据 bytes 追加到缓冲区末尾。如果缓冲区容量不足,动态扩展缓冲区。
void dbuf_destroy(struct dynbuf *dbuf) //释放缓冲区的内存及其相关结构体
struct dynbuf *dbuf_create(size_t capacity, size_t grow_step) // 创建并初始化一个动态缓冲区结构体,分配初始容量和增长步长。
void dbuf_append_strf(struct dynbuf *dstr, const char *fmt, ...) // 将格式化后的字符串添加到 struct dynbuf 所指向的动态缓冲区中,并在必要时动态扩展缓冲区的大小执行时间和CPU频率
misc.h
// 架构特定的高精度时钟计数器函数
#elif defined(__x86_64__)
#define ACLK_HW_CLOCK
static __inline__ unsigned long long aclk_clock(void)
{
unsigned hi, lo;
__asm__ __volatile__ ("rdtsc" : "=a"(lo), "=d"(hi));
return ( (unsigned long long)lo)|( ((unsigned long long)hi)<<32 );
}
static inline unsigned long long aclk_freq(void) // 获取 CPU 频率。CPU 的频率越高,它在单位时间内执行的指令数量就越多,因此程序的执行速度也就越快。处理字符串的函数
misc.c
static size_t astr_nrof(char ch, char *str, size_t sz) // 统计并返回字符 ch 在字符串 str 中出现的次数,sz 表示字符串的长度。
char *astr_locof(char ch, char *str, size_t sz) // 在字符串 str 中查找字符 ch,并返回第一个出现位置的指针
int astr_free_str_array(char *arr[], size_t nr_entries) // 释放一个字符串数组 arr 中的所有字符串以及数组本身,nr_entries 是数组中的字符串数量。
int astr_split(char *str, char delim, char ***ptr_arr) // 将字符串 str 按照指定的分隔符 delim 进行分割,并将结果存储在字符串数组中。ptr_arr 指向结果数组。函数返回分割后的字符串数量。
int astr_to_int_array(char *str, char delim, int *ptr_arr[]) // 按照分隔符 delim 分割成多个子字符串,并将这些子字符串转换为整数,存储在 ptr_arr 指向的整数数组中。函数返回整数数组的元素数量。
char *astr_strf(const char *fmt, ...) // 生成格式化字符串。缓冲区的大小会动态扩展以适应生成的字符串。如果生成的字符串长度超过了当前缓冲区的大小,则缓冲区大小会成倍增加,直到能容纳完整的字符串为止。处理输入参数
misc.h
/* acop */
struct acop_option {
char short_name;
char *name;
int has_arg;
char *description;
void *arg;
void (*arg_handler)(struct acop_option *opt, char *arg);
};
misc.c
很多函数实现 生成概率分布
misc.h
// 表示一个概率分布区间
struct avgn_prob_dist_entry {
unsigned long long start_val;
unsigned long long end_val;
double prob;
};
// 包含一个概率分布区间数组和区间数量
struct avgn_prob_dist {
struct avgn_prob_dist_entry *entries;
int nr_entries;
};
misc.c
unsigned long long avgn_make_val(struct avgn_prob_dist *dist,
unsigned precision) // 函数根据给定的概率分布生成一个随机值。precision 控制生成概率的精度。函数通过随机数生成一个概率值,并在分布区间中找到相应的区间,然后返回该区间内的一个随机值???内存块操作
mics.c
int yamemcmp(const void *s1, const void *s2, size_t n) // 比较两个内存块 s1 和 s2 的前 n 个字节。如果内存块中的字节不相等,则返回 1;如果相等,则返回 0。
void *yamemcpy(void *dest, const void *src, size_t n) // 将源内存块 src 的前 n 个字节复制到目标内存块 dest。函数返回目标内存块的指针。以上都是关于程序运行时需要的代码部分,但是这个还有一个重要的要理解的部分是配置文件的数据怎么传过去,怎么运行起来的。
运行逻辑和流程——初始化
int main(int argc, char *argv[])
{
struct access_config config;
struct argp argp = {
.options = options,
.parser = parse_option,
.args_doc = "[config file]",
.doc = "Simulate given memory access pattern\v"
"\'config file\' argument is optional."
" It defaults to \'configs/default\'",
};
int i;
// 这里应该是解析命令行参数。解析完成后,将解析结果存储在argp结构体中
argp_parse(&argp, argc, argv, ARGP_IN_ORDER, NULL, NULL);
// 数字格式的区域设置。
setlocale(LC_NUMERIC, "");
for (i = 0; i < nr_repeats; i++) {
read_config(config_file, &config); // 传入的是路径和访问的结构体
……
}
return 0;
}
struct mregion {
char name[256];
size_t sz;
char *region;
};
void read_config(char *cfgpath, struct access_config *config_ptr)
{
struct stat sb;
char *cfgstr;
int f;
char *content;
int len_paragraph;
size_t nr_regions;
struct mregion *mregions;
size_t nr_phases;
struct phase *phases;
f = open(cfgpath, O_RDONLY);
if (f == -1)
err(1, "open(\"%s\") failed", cfgpath);
if (fstat(f, &sb)) // 文件的状态存储在sb结构体中
err(1, "fstat() for config file (%s) failed", cfgpath);
// 分配内存以存储文件内容,并使用 readall 函数将文件内容读入 cfgstr,然后关闭文件
cfgstr = (char *)malloc(sb.st_size * sizeof(char));
readall(f, cfgstr, sb.st_size);
close(f);
// 使用 rm_comments 函数移除文件内容中的注释,并释放 cfgstr 所占用的内存
content = rm_comments(cfgstr, sb.st_size);
free(cfgstr);
// 使用 paragraph_len 函数计算第一个段落的长度(通过两个连续的回车符号),如果返回 -1,则表示文件格式错误。然后将段落的结束标记为 '\0'。
len_paragraph = paragraph_len(content, strlen(content));
if (len_paragraph == -1)
err(1, "Wrong file format");
content[len_paragraph] = '\0';
// 并使用 parse_regions 函数解析该段落中的内存区域信息,存储在 mregions中(每个区域是mregion[i]的数组的形式被组织),并获取区域数量 nr_regions
nr_regions = parse_regions(content, &mregions);
// 指向字符的指针,每个字符占用一个字节.
content += len_paragraph + 2; /* plus 2 for '\n\n' */
nr_phases = parse_phases(content, &phases, nr_regions, mregions);
config_ptr->regions = mregions;
config_ptr->nr_regions = nr_regions; //共有多少区域
config_ptr->phases = phases;
config_ptr->nr_phases = nr_phases;
}
struct phase {
char *name; // 运行阶段名
unsigned time_ms; // 运行时间
struct access *patterns; //
int nr_patterns; // 该阶段有多少访问模式(多少个区域要设置访问,阶段内行数-2)
/* For runtime only */
int total_probability;
};
size_t parse_phases(char *str, struct phase **phases_ptr,
size_t nr_regions, struct mregion *regions)
{
struct phase *phases;
struct phase *p;
size_t nr_phases;
char **lines_orig;
char **lines;
int nr_lines;
int nr_lines_paragraph;
int i, j;
nr_phases = 0;
nr_lines = astr_split(str, '\n', &lines_orig);
lines = lines_orig;
if (nr_lines < 4) /* phase name, time, nr patterns, pattern */
err(1, "Not enough lines for phases %s", str);
// 通过统计空行的数量来确定阶段数量,因为每个阶段的定义之间有一个空行
for (i = 0; i < nr_lines; i++) {
if (lines_orig[i][0] == '\0')
nr_phases++;
}
// 阶段数量分配存储阶段信息的数组
phases = (struct phase *)malloc(nr_phases * sizeof(struct phase));
for (i = 0; i < nr_phases; i++) {
nr_lines_paragraph = 0; // 对每个阶段,统计其包含的行数
for (j = 0; j < nr_lines; j++) {
if (lines[j][0] == '\0')
break;
nr_lines_paragraph++;
}
p = &phases[i];
lines += parse_phase(&lines[0], nr_lines_paragraph,
p, nr_regions, regions) + 1; // 对每个阶段里的每一行做处理, 因为每一行的操作和regions有关,结果存在p里面
}
astr_free_str_array(lines_orig, nr_lines);
*phases_ptr = phases;
return nr_phases;
}
int parse_phase(char *lines[], int nr_lines, struct phase *p,
size_t nr_regions, struct mregion *regions)
{
// 将阶段结构体和每个阶段访问模式结构体初始化
struct access *patterns;
char **fields;
int nr_fields;
struct access *a;
int j, k;
if (nr_lines < 3)
errx(1, "%s: Wrong number of lines! %d\n", __func__, nr_lines);
// 初始化每个阶段
p->name = (char *)malloc((strlen(lines[0]) + 1) * sizeof(char));
strcpy(p->name, lines[0]);
p->time_ms = atoi(lines[1]);
p->nr_patterns = nr_lines - 2;
p->total_probability = 0;
lines += 2;
patterns = (struct access *)malloc(p->nr_patterns *
sizeof(struct access));
p->patterns = patterns;
// 每个阶段内对多个区域的访问模式
for (j = 0; j < p->nr_patterns; j++) {
nr_fields = astr_split(lines[0], ',', &fields);
if (nr_fields != 4 && nr_fields != 5)
err(1, "Wrong number of fields! %s\n",
lines[0]);
a = &patterns[j];
a->mregion = NULL;
for (k = 0; k < nr_regions; k++) {
if (strcmp(fields[0], regions[k].name) == 0) {
a->mregion = ®ions[k];
}
}
if (a->mregion == NULL)
err(1, "Cannot find region with name %s",
fields[0]);
a->random_access = atoi(fields[1]);
a->stride = atoi(fields[2]);
a->probability = atoi(fields[3]);
if (nr_fields == 5) {
a->rw_mode = parse_rwmode(fields[4]);
} else {
a->rw_mode = default_rw_mode;
}
a->prob_start = p->total_probability;
a->last_offset = 0;
lines++;
astr_free_str_array(fields, nr_fields);
p->total_probability += a->probability;
}
return 2 + p->nr_patterns;
}
struct access {
struct mregion *mregion; //属于哪个初始区域的
int random_access; // 是否随机访问
size_t stride; // 步幅(每次访问的偏移量)
int probability; // 访问概率
enum rw_mode rw_mode;
/* For runtime only */
int prob_start; // 概率起始值(仅在运行时使用)
size_t last_offset; // 上次访问的偏移量(仅在运行时使用)
};
// 两个于阶段有关的函数处理完后回到read_config函数,最后一步初始化access_config结构体,这里将所有配置文件和运行方案都集中到了一个指针。
struct access_config {
struct mregion *regions; // 总的区域数组
ssize_t nr_regions;
struct phase *phases; // 总的阶段数组
ssize_t nr_phases;
};
// 再回到主函数
int main(int argc, char *argv[])
{
……
for (i = 0; i < nr_repeats; i++) {
……
// 通过预生成随机数并存储在数组中,可以减少在运行时频繁调用rand()函数的开销,从而提高性能
init_rndints();
// 执行配置文件的要求
exec_config(&config);
}
return 0;
}运行逻辑和流程——执行
void exec_config(struct access_config *config) // 通过这个结构体中所有region指针数组,(按照读取配置文件中的顺序)分配相应内存空间,空间地址由结构体成员char*region保存。
// 对于每个阶段执行
exec_phase(&config->phases[i]);
//函数再次遍历每个内存区域,如果使用大页,使用munmap取消映射大页内存;否则,使用free释放普通内存。
void exec_phase(struct phase *phase)
{
struct access *pattern;
unsigned long long nr_access;
unsigned long long start;
int randn;
size_t i;
static unsigned long long cpu_cycle_ms;
// cpu_cycle_ms 是一个静态变量,表示每毫秒的CPU周期数。它在第一次执行时被初始化,以后每次调用该函数时都不会重新初始化
if (!cpu_cycle_ms)
cpu_cycle_ms = aclk_freq() / 1000;
// start 记录了当前的时钟周期数,nr_access 记录访问次数,初始化为0
start = aclk_clock();
nr_access = 0;
// 如果 hintmethod 不为 NONE,则调用 hint_access_pattern 函数对内存访问模式进行提示
if (hintmethod != NONE)
hint_access_pattern(phase);
while (1) {
randn = rndint() % phase->total_probability; // 生成一个随机数 randn,范围在 0 到 phase->total_probability 之间
for (i = 0; i < phase->nr_patterns; i++) {
int prob_start, prob_end;
pattern = &phase->patterns[i];
prob_start = pattern->prob_start;
prob_end = prob_start + pattern->probability; //这是用户定义的
if (randn >= prob_start && randn < prob_end) // 如果随机数在这个区间内,那就去访问
nr_access += do_access(pattern);
}
if (aclk_clock() - start > cpu_cycle_ms * phase->time_ms) // 通过比较当前时钟周期数与起始时钟周期数的差值,判断是否超过该阶段的预定运行时间 phase->time_ms
break;
}
if (!quiet) // 如果 quiet 标志未设置,打印该阶段的名称、每毫秒的访问次数以及运行时间
printf("%s:\t%'20llu accesses/msec, %llu msecs run\n",
phase->name,
nr_access /
((aclk_clock() - start) / cpu_cycle_ms),
((aclk_clock() - start) / cpu_cycle_ms));
}给每个区域分配内存空间
for (i = 0; i < config->nr_regions; i++) {
region = &config->regions[i];
if (use_hugetlb) {
region->region = mmap(HUGETLB_ADDR, region->sz,
HUGETLB_PROTECTION, HUGETLB_FLAGS, -1,
0);
if (region->region == MAP_FAILED) {
perror("mmap");
exit(1);
}
} else {
region->region = (char *)malloc(region->sz);
}
// 访问内存,确保物理内存分配,否则这个惯例是按需分配(lazy allocation),无论使用 mmap 还是 malloc物理内存页帧会在首次访问时分配,而不是在分配虚拟地址空间时立即分配。
memset(region->region, 0, region->sz);
}
