虽然大页一直被人嫌弃,因为内存碎片化带来的页面规整开销和大页面分配困难、访问倾斜等。但是“存在即合理”。大页还是有些优势的比如在大内存中增加TLB的覆盖等。许多针对TLB和页面粒度大小的研究也一直没停过。PS. huge page 到底怎么写好像没有明确的说法。
- 参考Transparent Hugepages: measuring the performance impact解释了透明大页的优缺点,但是主要还是讲了3个测量大页性能的方法。最后面有一个测试案列不错。
- 了解透明巨页支持的最佳处是Linux内核网站上的官方文档。
- /proc/buddyinfo 让你了解 Linux 机器上的可用内存碎片。您可以查看每个可用订单的空闲片段,每个numa节点的不同区域。
0. 大页面
地址转换逻辑(页表遍历)由CPU的内存管理单元(MMU) 实现。MMU还具有最近使用的页面的缓存。此缓存称为转换后备缓冲区(TLB) 。
虚拟地址需要转换为物理地址时,首先搜索TLB。如果找到匹配项(TLB命中),则返回物理地址,并且可以继续内存访问。但是,如果没有匹配项(称为TLB未命中),MMU通常会在页表中查找地址映射,以查看映射是否存在。页表遍历很昂贵,因为它可能需要多次内存访问(但它们可能会命中CPUL1/L2/L3缓存)。另一方面,TLB缓存大小有限,通常可以容纳数百页。
在任何分页系统中,都需要考虑两个主要问题:
1)虚拟地址到物理地址的映射必须非常快。
2)如果虚拟地址空间很大,页表也会很大。
第一个问题是由于每次访向内存都需要进行虚拟地址到物理地址的映射,所有的指令最终都必须来自内存,并且很多指令也会访问内存中的操作数。因此,每条指令进行一两次或更多页表访问是必要的。如果执行一条指令需要1ns,页表查询必须在0.2ns之内完成,以避免映射成为一个主要瓶颈。
第二个问题来自现代计算机使用64位变得越来越普遍。假设页面大小为4KB,32位的地址空间将有100万页,而64位地址空间简直多到超乎想象。如果虚拟地址空间中有100万页,那么页表必然有100万条表项。另外请记住,每个进程都需要自己的页表(因为它有自己的虚拟地址空间)。(《现代操作系统》第4版,还有很多很清晰的讨论P114)
第一个是增加TLB大小,这很昂贵,而且不会有很大帮助(因为页表项增加后查找将变慢)。另一个是增加页面大小,因此要映射的页面更少。现代操作系统和CPU支持2MB甚至1GB的大页面。使用2MB的大页面,128GB内存变为64000页。
使用更大的内存页作为映射单位有如下好处:
- 减少 TLB(Translation Lookaside Buffer) 的失效情况(或者说减少page walk)。
- 减少 页表 的内存消耗。
- 减少 PageFault(缺页中断)的次数。
有两个因素可以作为选择小页面的理由。随便选择一个数据很可能不会恰好装满整数个页面,多余的空间就被浪费掉了,这种浪费称为内存膨胀。另外分配大页需要连续的物理地址空间,多次分配后造成内部碎片(internal fragmentation)使得大页分配困难,需要额外后台线程做内存规整。
1. static huge page静态大页面
静态huge page是不支持swap操作的,不能被换出到外部存储介质上。页面大小小于MAX_ORDER的大页称之为huge page,大于等于MAX_ORDER的大页称之为gigantic page,拿常用的举例,2MB是huge page,1GB是gigantic page。
huge page和gigantic page走的是不同的分配路径。huge page相对较小,所以通过伙伴系统来分配(注意:虽然走伙伴系统,但最终它的元数据设置和普通伙伴系统页面的设置是分开处理的)。分配走的是伙伴系统核心都是alloc_huge_page,在大页系统初始化的时候,也会通过alloc_huge_page接口,提前分配物理页。
在向伙伴系统申请一个大页时,如果是巨页,则优先通过CMA(Contiguous Memory Allocator)分配器分配,如果不支持CMA或者CMA内存不足,则通过指定范围连续物理页申请接口(alloc_contig_pages)而gigantic page页面较大,伙伴系统无法满足分配要求,所以通过连续内存分配接口alloc_contig_range()
标准大页存在两个严重的问题:
1、需要提前预分配好大页内存池,通过内核启动参数或者虚拟文件系统的方式。
2、对代码进行嵌入修改,例如使用mmap时,需要添加MAP_HUGETLB配置;或者需要挂载大页文件系统;或者使用libhugetlbfs提供的方法等。
针对64位的x86-64系统,huge page的大小是2MB或者1GB,初始数目由启动时的”vm.nr_hugepages“ 内核参数确定,对于2MB的huge page,运行过程中可通过”/proc/sys/vm/nr_hugepages“修改。但对于1GB的huge page,就只能在启动时分配(且分配后不能释放),而不支持在运行时修改(系统起来后再要倒腾出1GB连续的物理内存,也怪难为内核的)
预留大页面的方式需要在启动内核时应用配置优点是开机时就通过bootmem分配大页,不存在因为内存碎片导致分不出大页的情况,从而保证预留的成功。需要指出的是,系统能否支持大页,支持大页的大小为多少是由其使用的处理器决定的。通过在bootargs传参在系统启动过程中预留大页,bootargs参数:预分配大页数量hugepages= 和 预分配大页的大小hugepagesz= ,更详细的使用可参看内核文档kernel-parameters.txt
# 假如我们想保留64个大页面,每个2MB,就用下面的配置:
hugepagesz = 2MB, hugepages = 64
# 还可以指定默认的大页大小。比如,我们想预留4GB内存作为大页使用,大页的大小为1GB,那么可以用以下的命令行:
default_hugepagesz=1G hugepagesz=1G hugepages=4在Linux启动之后,如果想预留大页,则可以使用以下的方法来预留内存。
# 在非NUMA系统中,可以使用以下方法预留2MB大小的大页。
echo 24 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
# 该命令预留24个大小为2MB的大页,也就是预留了2GB内存。
# 如果是在NUMA系统中,假设有两个NODE的系统中,则可以用以下的命令:
echo 24 > /sys/devices/system/node/node0/hugepages/hugepages-2048kB/nr_hugepages
echo 24 > /sys/devices/system/node/node1/hugepages/hugepages-2048kB/nr_hugepages
# 或者
echo 20 > /proc/sys/vm/nr_hugepages #设置20页大页
#或者
echo 5 > /sys/kernel/mm/hugepages/hugepages-1048576kB/nr_hugepages
/**
* 含义:通过sysfs下的文件节点申请和释放大页,保持系统中1GB的大页有5个。
* 若已经存在5个大页则什么都不做;若少于5个则分配够5个;
* 若多于5个则释放多余的大页(前提是未被使用)。
**/
cat /sys/kernel/mm/hugepages/hugepages-2048kB/free_hugepages
// 含义:查看系统中空闲的的2MB大页的数量如果希望在不修改源码的情况下运行一个程序(如 redis-server)并让它使用静态大页(HugeTLB),可以通过以下方式实现:
确保系统中已经安装了 libhugetlbfs 库。
sudo apt-get install libhugetlbfs-bin
sudo yum install libhugetlbfs
sudo find / -name "libhugetlbfs.so"查看是否已经按照之前的方式分配了大页面
grep Hugepagesize /proc/meminfo在运行希望使用大页面的程序时:
LD_PRELOAD=/usr/lib/libhugetlbfs.so HUGETLB_MORECORE=yes XXX程序运行命令LD_PRELOAD=/usr/lib/libhugetlbfs.so:通过预加载libhugetlbfs库,强制应用程序使用静态大页。HUGETLB_MORECORE=yes:该环境变量告诉libhugetlbfs将malloc分配的大内存使用静态大页。
使用 libhugetlbfs 结合 LD_PRELOAD,可以在不修改程序源码的情况下让程序使用静态大页。这种方式适用于大多数需要使用静态大页的应用场景。
2. THP
复合页(Compound Page)就是将物理上连续的两个或多个页看成一个独立的大页,它能够用来创建hugetlbfs中使用的大页(hugepage)。也能够用来创建透明大页(transparent huge page)。可是它不能用在页缓存(page cache)中,这是由于页缓存中管理的都是单个页。分配一个复合页的方式是:使用alloc_pages函数,參数order至少为1,且设置__GFP_COMP标记。由于依据复合页的定义,它通常包含2个或多个连续的物理内存页,这是由它的实现决定的,因而order参数不可能为0。
transparent huge page透明大页。在Linux中自2.6.38版本开始支持THP。在应用需要huge page的时候,可通过memory compaction(内存规整)操作移动页面,以形成一个huge page,因为该过程不会被应用感知到,所以被称为”transparent”。
struct page {
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
union { // 这个结构中每个struct代表一种页面类型
...
struct { /* Tail pages of compound page */
// 对于尾页面(tail page),这个字段指向对应的头页面(head page)的地址
// 位0被置为1(通过位操作实现),表示这是一个尾页面
// 不被置为1,那么就是Head page保存整个复合页面的信息
unsigned long compound_head; /* Bit zero is set */
/* First tail page only */
unsigned char compound_dtor; // 在头页面中指定了复合页面的析构函数
unsigned char compound_order; // 表示该复合页面的阶数(order)。
// 对于透明大页面(2MB的页面),compound_order=9,因为2^9 = 512个4KB的基础页面
atomic_t compound_mapcount; // 用于跟踪该复合页面被映射到用户空间的次数
unsigned int compound_nr; /* 1 << compound_order */
// 指定该复合页面包含的基础页面数目,例如1 << 9 = 512
};
struct { /* Second tail page of compound page */
unsigned long _compound_pad_1; /* compound_head 指向复合页面的头页面 */
atomic_t hpage_pinned_refcount; // 在被分解时需要处理额外的引用计数?
/* For both global and memcg */
struct list_head deferred_list; // 延迟释放大页面
};
...
}
...
}THP采用常规(“高阶”)内存分配路径,它要求操作系统能够找到连续且对齐的内存块。它与常规页面存在相同的问题,即碎片化。如果操作系统找不到连续的内存块,它将尝试压缩、回收或分页其他页面。**该过程成本高昂,可能会导致延迟峰值(长达几秒钟)**。此问题已在4.6 内核中得到解决(通过”延迟”选项),如果操作系统无法分配大页面,则会回退到常规页面。
维护。即使应用程序只接触1字节的内存,它也会占用整个2MB的大页面。这显然是浪费内存。所以有一个名为khugepaged的后台内核线程。它扫描页面并尝试对其进行碎片整理并折叠成一个巨大的页面。尽管它是一个后台线程,但它会锁定它使用的页面,因此也可能导致延迟峰值。另一个陷阱在于大页面拆分,并非操作系统的所有部分都适用于大页面,例如Swap。操作系统将大页面拆分为常规页面。它还可能降低性能并增加内存碎片。
实现THP作为一个整体被swap out和swap in(参考这篇文章)
运行以下命令检查透明大页的状态:
cat /sys/kernel/mm/transparent_hugepage/enabled如果输出为 [always] madvise never,则透明大页功能已经开启。
如果输出为 always madvise [never],则透明大页功能已经关闭。
如果透明大页功能未开启,可以通过以下命令启用它(需要管理员权限)
echo always > /sys/kernel/mm/transparent_hugepage/enabled调整透明大页配置,有两个可用的配置选项,分别是 transparent_hugepage/defrag 和 transparent_hugepage/enabled。transparent_hugepage/defrag:用于设置大页碎片整理的方式。transparent_hugepage/enabled:用于设置大页的启用方式。
echo always > /sys/kernel/mm/transparent_hugepage/defrag
echo always > /sys/kernel/mm/transparent_hugepage/enabled自己整理的大页面申请流程: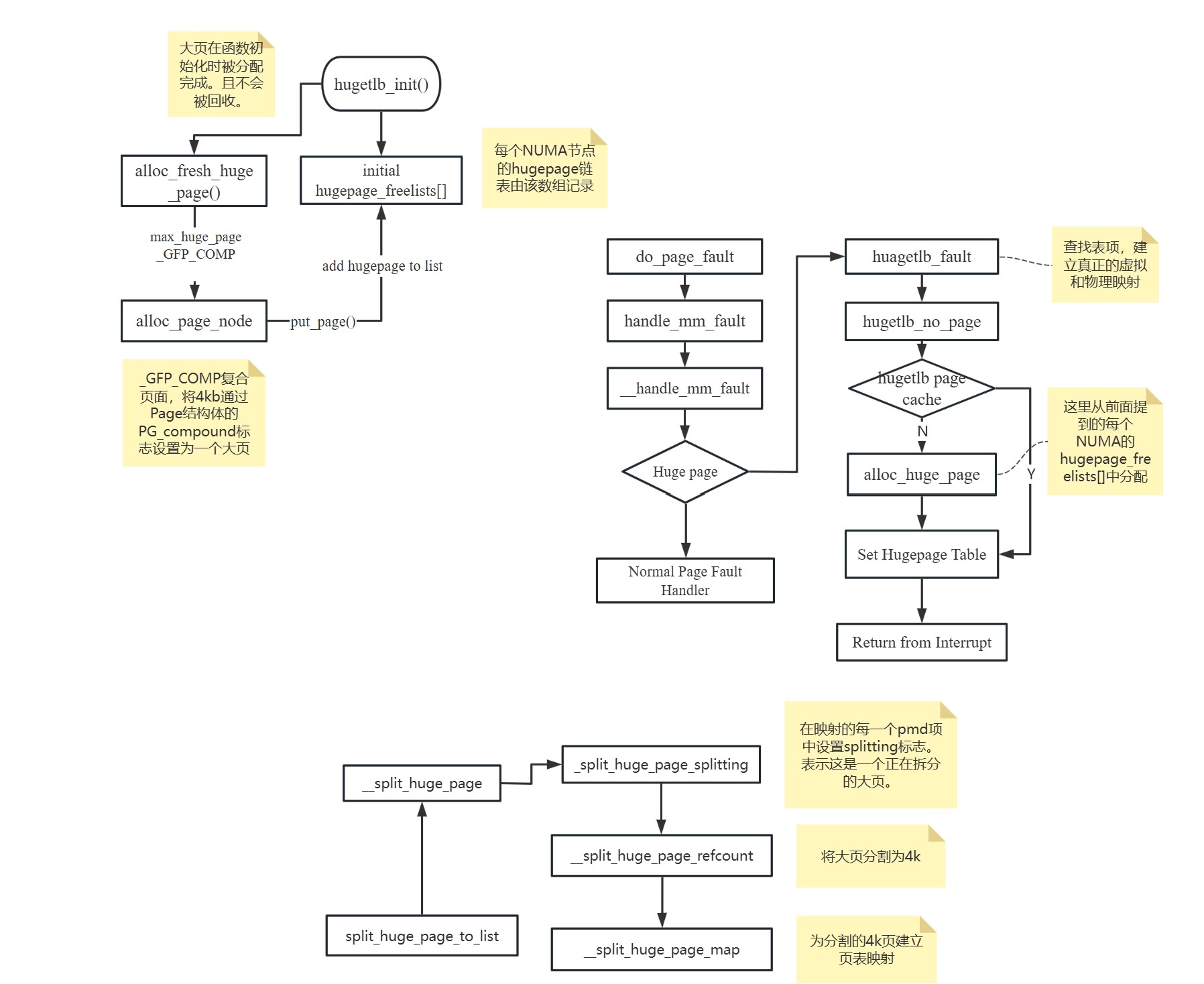
参考Huge Page 是否是拯救性能的万能良药?可以有参考。
参考透明巨页:衡量性能影响
3. 页表
PGD (Page Global Directory) → P4D → PUD → PMD → PTE每一级页表存储下一级页表的地址,最终PTE(Page Table Entry)指向实际的物理页。一个PMD直接指向2MB的物理页(跳过PTE层级);一个PUD直接指向 1GB 的物理页(跳过PMD和PTE层级)。在Linux中,页表本身(比如PTE、PMD、PUD表)都是由实际的物理页面承载的。struct mm_struct是每个进程唯一的地址空间结构,进程的所有内存映射信息都在这。当你在内核中分配一个页表页(通常在处理page fault或mmap时),你从物理页池中拿一个4KB页面作为页表。内核通过struct page管理这个物理页,它需要知道这个页表页是为哪个进程分配的。页表页属于某个进程,需要知道归属。
// 存页表的物理页面的struct page中的union
struct {
unsigned long _pt_pad_1; // 填充字段,用于对齐或覆盖共用结构
pgtable_t pmd_huge_pte; // 和THP拆分有关
unsigned long _pt_pad_2; // 填充字段
union {
struct mm_struct *pt_mm; // 指向拥有该页表页的进程的mm_struct
atomic_t pt_frag_refcount; // 在部分架构中用于页表碎片引用计数
};
#if ALLOC_SPLIT_PTLOCKS
spinlock_t *ptl; // 指向外部页表锁
#else
spinlock_t ptl; // 内嵌页表锁(节省空间)
#endif
};4. TLB
通过编译优化来将频繁被访问的指令汇总到一起,放在二进制文件中的同一个地方,以提高空间局部性,这样就可以提高iTLB命中。这块放置频繁访问指令的区域,就叫热区域(Hot Text)。
通过在大页面上放置热文本,可以进一步提升iTLB命中率。使用大页面iTLB条目时,单个TLB条目覆盖的代码是标准4K页面的512倍。更重要的是,当代的CPU体系结构,通常为大页面提供一些单独的TLB条目,如果我们不使用大页面,这些条目将处于空闲状态。(是吗?待考证)所以,通过使用大页面,也可以充分利用那些TLB条目。
关于分支预测的基础知识。如果从运行的二进制文件来优化iTLB,可以考虑LBR(Last Branch Record,最后分支记录)为热函数创建优化表单HFSort工具。
事实上,perf只支持所有事件的一个小子集,而CPU有数百个不同的计数器来监测性能。
在页表中遍历所花费的 CPU 周期数
[~]# perf stat -e cycles \
> -e cpu/event=0x08,umask=0x10,name=dcycles/ \
> -e cpu/event=0x85,umask=0x10,name=icycles/ \
> -a -I 1000
# time counts unit events
1.005079845 227,119,840 cycles
1.005079845 2,605,237 dcycles
1.005079845 806,076 icycles由 TLB 未命中引起的主内存读取次数;这些读取会错过 CPU 缓存,因此非常昂贵
[root@PRCAPISV0003L01 ~]# perf stat -e cache-misses \
> -e cpu/event=0xbc,umask=0x18,name=dreads/ \
> -e cpu/event=0xbc,umask=0x28,name=ireads/ \
> -a -I 1000
# time counts unit events
1.007177568 25,322 cache-misses
1.007177568 23 dreads
1.007177568 5 ireads5. 伙伴系统内存分配的碎片
随着时间的推移,分配请求将拆分、合并、拆分…这个池,直到我们到达由于缺少连续内存块而可能不得不使请求失败的地步。在这种情况下,buddyinfo proc 文件将允许您查看内存的当前碎片状态。这是一个快速的python脚本。
#!/usr/bin/env python
# vim: tabstop=4 expandtab shiftwidth=4 softtabstop=4 textwidth=79 autoindent
"""
Python source code
Last modified: 15 Feb 2014 - 13:38
Last author: lmwangi at gmail com
Displays the available memory fragments
by querying /proc/buddyinfo
Example:
# python buddyinfo.py
"""
import optparse
import os
import re
from collections import defaultdict
import logging
class Logger:
def __init__(self, log_level):
self.log_level = log_level
def get_formatter(self):
return logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
def get_handler(self):
return logging.StreamHandler()
def get_logger(self):
"""Returns a Logger instance for the specified module_name"""
logger = logging.getLogger('main')
logger.setLevel(self.log_level)
log_handler = self.get_handler()
log_handler.setFormatter(self.get_formatter())
logger.addHandler(log_handler)
return logger
class BuddyInfo(object):
"""BuddyInfo DAO"""
def __init__(self, logger):
super(BuddyInfo, self).__init__()
self.log = logger
self.buddyinfo = self.load_buddyinfo()
def parse_line(self, line):
line = line.strip()
self.log.debug("Parsing line: %s" % line)
parsed_line = re.match("Node\s+(?P<numa_node>\d+).*zone\s+(?P<zone>\w+)\s+(?P<nr_free>.*)", line).groupdict()
self.log.debug("Parsed line: %s" % parsed_line)
return parsed_line
def read_buddyinfo(self):
buddyhash = defaultdict(list)
buddyinfo = open("/proc/buddyinfo").readlines()
for line in map(self.parse_line, buddyinfo):
numa_node = int(line["numa_node"])
zone = line["zone"]
free_fragments = map(int, line["nr_free"].split())
max_order = len(free_fragments)
fragment_sizes = self.get_order_sizes(max_order)
usage_in_bytes = [block[0] * block[1] for block in zip(free_fragments, fragment_sizes)]
buddyhash[numa_node].append({
"zone": zone,
"nr_free": free_fragments,
"sz_fragment": fragment_sizes,
"usage": usage_in_bytes })
return buddyhash
def load_buddyinfo(self):
buddyhash = self.read_buddyinfo()
self.log.info(buddyhash)
return buddyhash
def page_size(self):
return os.sysconf("SC_PAGE_SIZE")
def get_order_sizes(self, max_order):
return [self.page_size() * 2**order for order in range(0, max_order)]
def __str__(self):
ret_string = ""
width = 20
for node in self.buddyinfo:
ret_string += "Node: %s\n" % node
for zoneinfo in self.buddyinfo.get(node):
ret_string += " Zone: %s\n" % zoneinfo.get("zone")
ret_string += " Free KiB in zone: %.2f\n" % (sum(zoneinfo.get("usage")) / (1024.0))
ret_string += '\t{0:{align}{width}} {1:{align}{width}} {2:{align}{width}}\n'.format(
"Fragment size", "Free fragments", "Total available KiB",
width=width,
align="<")
for idx in range(len(zoneinfo.get("sz_fragment"))):
ret_string += '\t{order:{align}{width}} {nr:{align}{width}} {usage:{align}{width}}\n'.format(
width=width,
align="<",
order = zoneinfo.get("sz_fragment")[idx],
nr = zoneinfo.get("nr_free")[idx],
usage = zoneinfo.get("usage")[idx] / 1024.0)
return ret_string
def main():
"""Main function. Called when this file is a shell script"""
usage = "usage: %prog [options]"
parser = optparse.OptionParser(usage)
parser.add_option("-s", "--size", dest="size", choices=["B","K","M"],
action="store", type="choice", help="Return results in bytes, kib, mib")
(options, args) = parser.parse_args()
logger = Logger(logging.DEBUG).get_logger()
logger.info("Starting....")
logger.info("Parsed options: %s" % options)
print logger
buddy = BuddyInfo(logger)
print buddy
if __name__ == '__main__':
main()回收的时候要被怎么拆分?
https://lore.kernel.org/linux-mm/20230913164938.16918-1-vernhao@tencent.com/
https://patchew.org/linux/20230912021727.61601-1-vernhao@tencent.com/

