memtis的源码分为很多个部分,对页表的修改,支持混合页面,硬件计数器采样,采样开销控制,页面迁移等。
1. 硬件计数器采样
1.1 内核perf架构
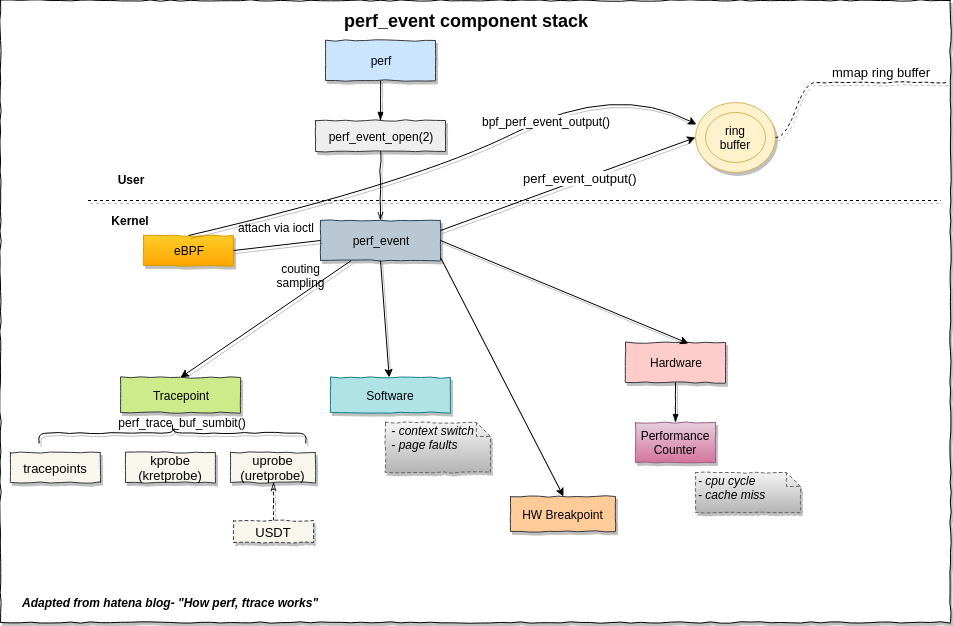
写硬件计数器采样程序,涉及这幅图的软件、硬件事件,以及用户空间中的ring buffer.
唯一的用户态系统调用会返回一个perf事件的句柄,这样这个perf_event结构可以通过read/write/ioctl/mmap通用文件接口来操作。perf_event_open(2)的调用也是挺复杂的,详细操作可以看perf_event_open(2) Linux manual page,后面写采样后台线程用到了会详细说。
perf_event也是内核中比较核心的结构体,性能事件有多种类型,例如跟踪点、软件、硬件。这些又具体表现为PMU结构体,每一个事件都有一个,比如software pmu:
static struct pmu perf_swevent = {
.task_ctx_nr = perf_sw_context,
.capabilities = PERF_PMU_CAP_NO_NMI,
.event_init = perf_swevent_init,
.add = perf_swevent_add,
.del = perf_swevent_del,
.start = perf_swevent_start,
.stop = perf_swevent_stop,
.read = perf_swevent_read,
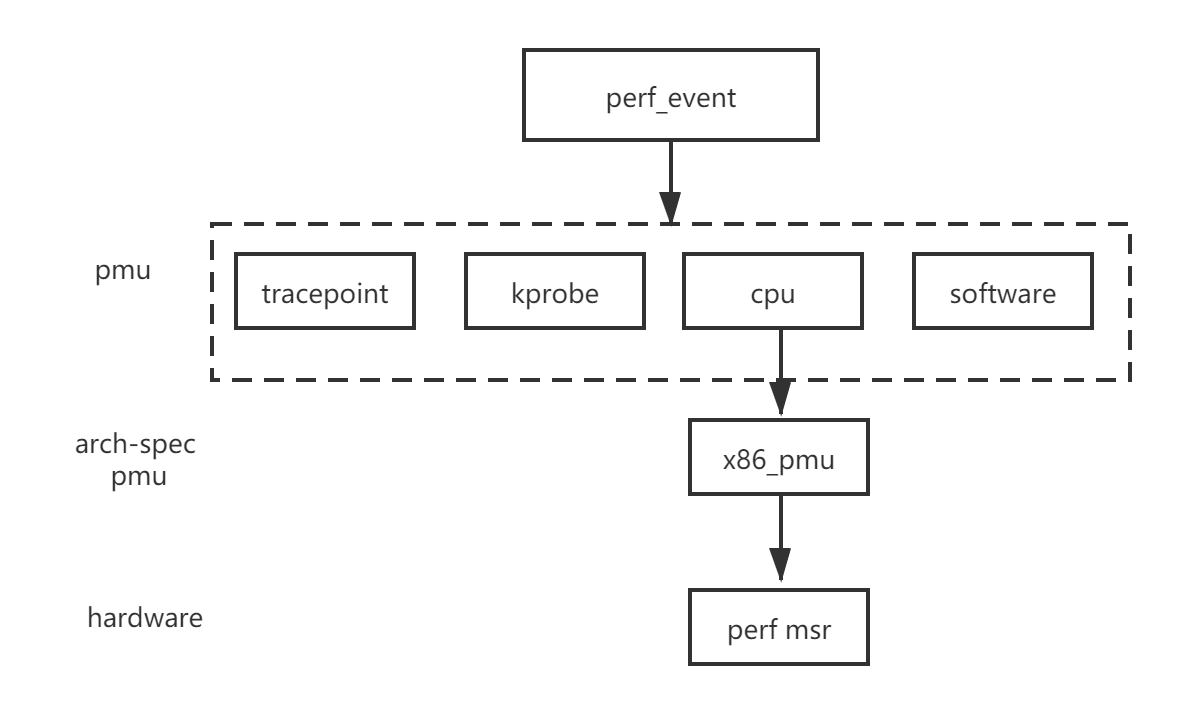
};如果这个事件是硬件相关,那么这个PMU结构体还会有一个和架构相关的结构体,如下图的struct x86_pmu, 这个硬件相关结构体的作用就是读或者写MSR性能监视器。
perf event的组织方式是cpu维度或者task维度,这样采样才不是只有整个系统的。在manual page有写,perf_event_open()系统调用使用cpu、pid两个参数来指定perf_event的cpu、task维度。两种维度的关联是靠perf_event_context如下图:
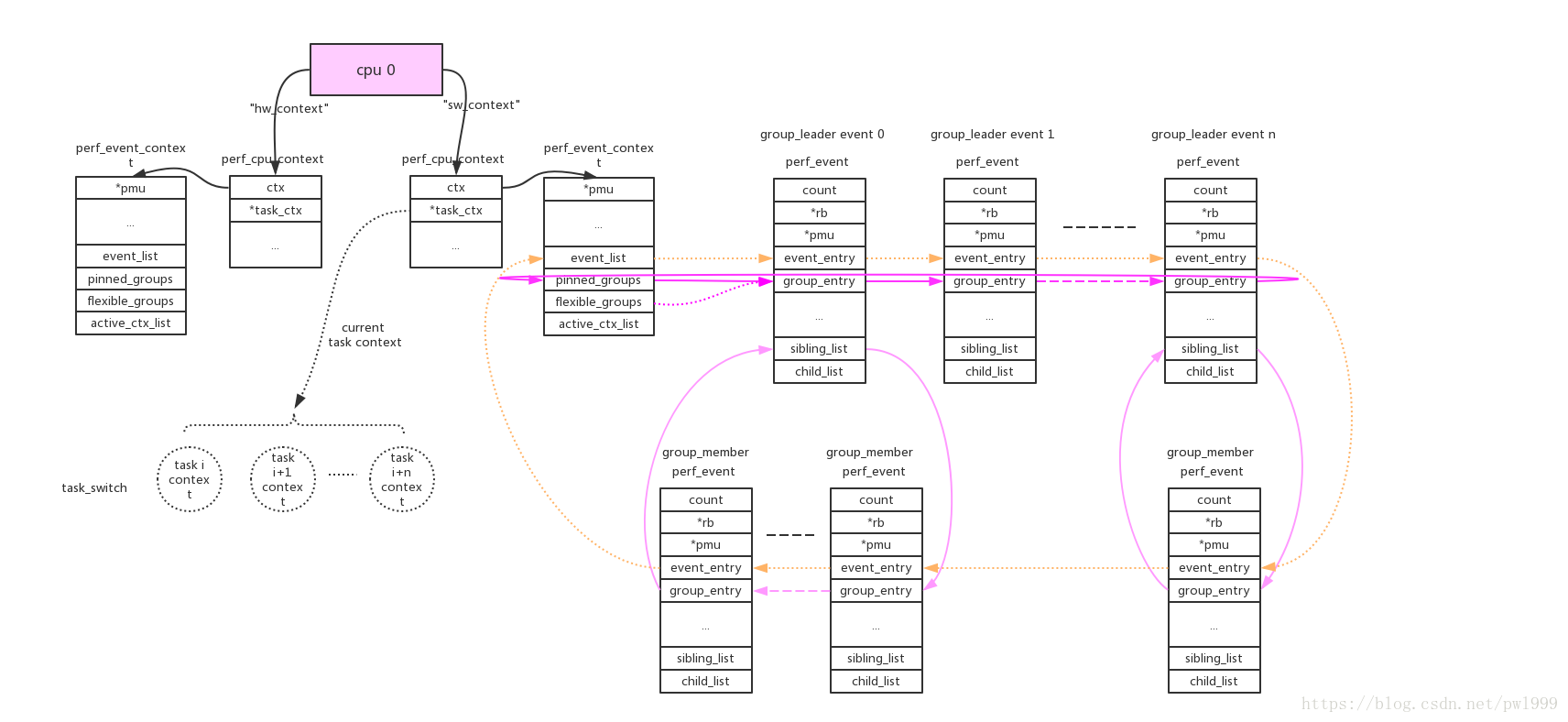
每个perf_event由event_list连接,而group的连接方式便于perf count功能一次性读出。
由于cpu维度的perf_event只要cpu online就会一直运行,task维度只有task被调度才会运行,这涉及perf驱动开关和任务调度。一个概括的函数调用图如下: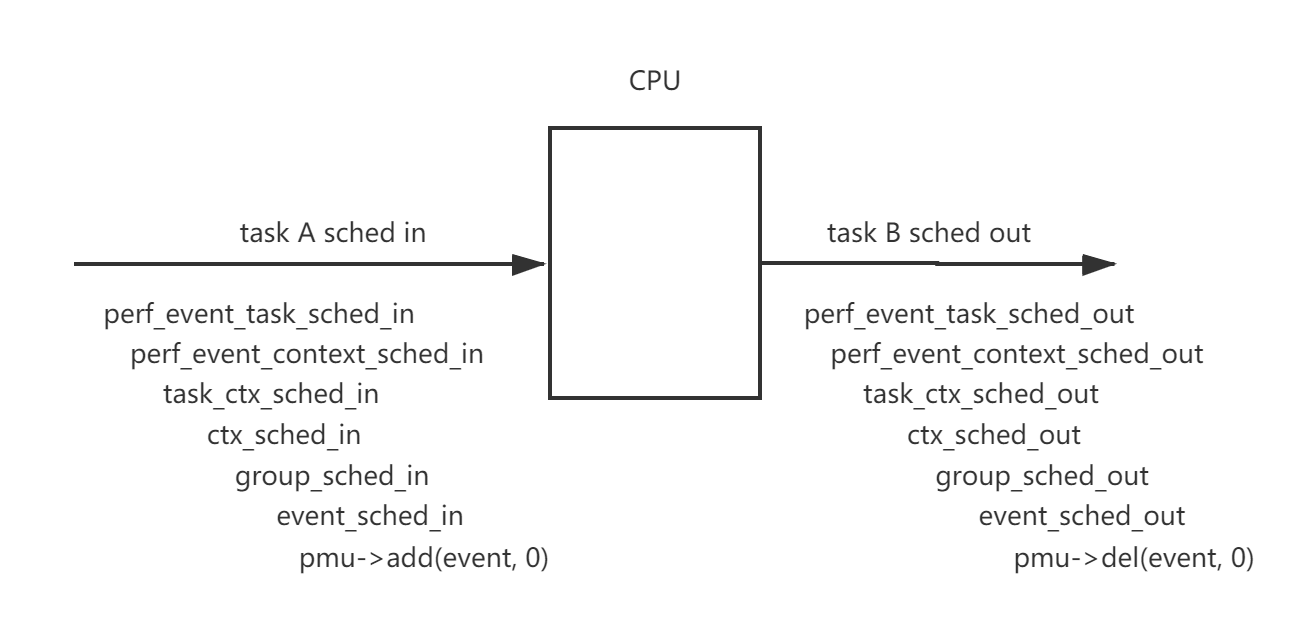
Every PMU is registerd by calling ‘perf_pmu_register’.
每个pmu拥有一个per_cpu的链表,perf_event需要在哪个cpu上获取数据就加入到哪个cpu的链表上。如果event被触发,它会根据当前的运行cpu给对应链表上的所有perf_event推送数据。

cpu维度的context:this_cpu_ptr(pmu->pmu_cpu_context->ctx)上链接的所有perf_event会根据绑定的pmu,链接到pmu对应的per_cpu的->perf_events链表上。
task维度的context:this_cpu_ptr(pmu->pmu_cpu_context->task_ctx)上链接的所有perf_event会根据绑定的pmu,链接到pmu对应的per_cpu的->perf_events链表上。perf_event还需要做cpu匹配,符合event->cpu == -1 || event->cpu == smp_processor_id()条件的event才能链接到pmu上。
参考Linux kernel perf architecture
参考Linux perf 1.1、perf_event内核框架
1.2 perf计数器模式
perf_event_open()有两个使用模式,一个叫做计数,一个叫做采样。计数事件会统计发生的总数,采样事件会定期写入缓冲区。下面来看一个非常简单的计数的代码段,每一秒获取刚刚过去的那一秒内的指令数:
#include <stdio.h>
#include <string.h>
#include <stdint.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <linux/perf_event.h>
//目前perf_event_open在glibc中没有封装,需要手工封装一下
int perf_event_open(struct perf_event_attr *attr,pid_t pid,int cpu,int group_fd,unsigned long flags)
{
return syscall(__NR_perf_event_open,attr,pid,cpu,group_fd,flags);
}
int main()
{
struct perf_event_attr attr;
memset(&attr,0,sizeof(struct perf_event_attr));
attr.size=sizeof(struct perf_event_attr);
//监测硬件
attr.type=PERF_TYPE_HARDWARE;
//监测指令数
attr.config=PERF_COUNT_HW_INSTRUCTIONS;
//初始状态为禁用
attr.disabled=1;
//创建perf文件描述符,其中pid=0,cpu=-1表示监测当前进程,不论运行在那个cpu上
int fd=perf_event_open(&attr,0,-1,-1,0);
if(fd<0)
{
perror("Cannot open perf fd!");
return 1;
}
//启用(开始计数)
ioctl(fd,PERF_EVENT_IOC_ENABLE,0);
while(1)
{
uint64_t instructions;
//读取最新的计数值
read(fd,&instructions,sizeof(instructions));
//读取后清零,这样就不用手动去减了,否则会显示累计值
ioctl(fd,PERF_EVENT_IOC_RESET,0);
printf("instructions=%ld\n",instructions);
sleep(1);
}
}不需要任何的编译选项,直接gcc,然后运行(从上个图我们知道这是用户态的函数):
gcc single.c -o single
sudo ./single对于多个计数器不能说搞多个文件句柄去读取,这样read()函数调用开销还是有点大的,重复利用一个句柄,这样就成了前面提到的组的关系。主要有以下6点不同。
#include <stdio.h>
#include <string.h>
#include <stdint.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <linux/perf_event.h>
//目前perf_event_open在glibc中没有封装,需要手工封装一下
int perf_event_open(struct perf_event_attr *attr,pid_t pid,int cpu,int group_fd,unsigned long flags)
{
return syscall(__NR_perf_event_open,attr,pid,cpu,group_fd,flags);
}
//1. 每次read()得到的结构体
struct read_format
{
//计数器数量(为2)
uint64_t nr;
//两个计数器的值
uint64_t values[2];
};
int main()
{
struct perf_event_attr attr;
// perf_event_attr structure provides detailed configuration information for the event being created.
//————————————————————第一个计数器—————————————————
memset(&attr,0,sizeof(struct perf_event_attr));
attr.size=sizeof(struct perf_event_attr);
//监测硬件
attr.type=PERF_TYPE_HARDWARE;
//监测指令数
attr.config=PERF_COUNT_HW_INSTRUCTIONS;
//初始状态为禁用
attr.disabled=1;
//2. 每次读取一个组
attr.read_format=PERF_FORMAT_GROUP;
//创建perf文件描述符,其中pid=0,cpu=-1表示监测当前进程,不论运行在那个cpu上
int fd=perf_event_open(&attr,0,-1,-1,0);
if(fd<0)
{
perror("Cannot open perf fd!");
return 1;
}
//————————————————————第二个计数器—————————————————
memset(&attr,0,sizeof(struct perf_event_attr));
attr.size=sizeof(struct perf_event_attr);
//监测类型
attr.type=PERF_TYPE_HARDWARE;
//监测时钟周期数
attr.config=PERF_COUNT_HW_CPU_CYCLES;
//初始状态为禁用
attr.disabled=1;
//3. 创建perf文件描述符,但是不同的是要传入上次的句柄
int fd2=perf_event_open(&attr,0,-1,fd,0);
if(fd2<0)
{
perror("Cannot open perf fd2!");
return 1;
}
//4. 启用(开始计数),注意PERF_IOC_FLAG_GROUP标志
ioctl(fd,PERF_EVENT_IOC_ENABLE,PERF_IOC_FLAG_GROUP);
while(1)
{
struct read_format aread;
//5.读取最新的计数值,每次读取一个结构体,每个计数器的读取和加入组的顺序是一致的。
read(fd,&aread,sizeof(struct read_format));
printf("instructions=%ld,cycles=%ld\n",aread.values[0],aread.values[1]);
//6. 清空组内计数器
ioctl(fd,PERF_EVENT_IOC_RESET,PERF_IOC_FLAG_GROUP);
sleep(1);
}
}1.3 perf采样
如果机器只运行一个程序,那么使用计数的方式也是可以的吧。但是如果要在多个里面追踪一个进程或特定的core那就得采样了,而且采样的好处在于可以获得更多的信息。
采样的模板主要在于:1、采样需要设置触发源,也就是告诉kernel何时进行一次采样;2、采样需要设置信号,也就是告诉kernnel,采样完成后通知谁;3、采样值的读取需要使用mmap,因为采样有异步性,需要一个环形队列,另外也是出于性能的考虑。通过轮询或者响应信号判断是否采样完这一轮。
采样事件准备工作:
//这些的定义得看cpu的架构手册
#define DRAM_LLC_LOAD_MISS 0x1d3
#define REMOTE_DRAM_LLC_LOAD_MISS 0x2d3
#define NVM_LLC_LOAD_MISS 0x80d1
#define ALL_STORES 0x82d0
#define ALL_LOADS 0x81d0
#define STLB_MISS_STORES 0x12d0
#define STLB_MISS_LOADS 0x11d0
static __u64 get_pebs_event(enum events e)
{
switch (e) {
case DRAMREAD:
return DRAM_LLC_LOAD_MISS;
case NVMREAD:
if (!htmm_cxl_mode)
return NVM_LLC_LOAD_MISS;
else
return N_HTMMEVENTS;
case MEMWRITE:
return ALL_STORES;
case CXLREAD:
if (htmm_cxl_mode)
return REMOTE_DRAM_LLC_LOAD_MISS;
else
return N_HTMMEVENTS;
default:
return N_HTMMEVENTS;
}
}
struct perf_event ***mem_event; //perf_event结构体数组,*mem_event是数组指针,因为是二维数组所以3*
static int pebs_init(pid_t pid, int node)
{
int cpu, event; //要采样的CPU数和事件数
//存放perf事件的空间被申请,是一个二维数组,每个core有一个专门存放的地方。
//kzalloc是内核空间内存申请函数,可以保证是连续的物理地址,但不能超过128KB,与kmalloc非常相似,只是这个会将申请到的内存清零。malloc是用户空间的。
mem_event = kzalloc(sizeof(struct perf_event **) * CPUS_PER_SOCKET, GFP_KERNEL);
for (cpu = 0; cpu < CPUS_PER_SOCKET; cpu++) {
mem_event[cpu] = kzalloc(sizeof(struct perf_event *) * N_HTMMEVENTS, GFP_KERNEL);
}
printk("pebs_init\n");
for (cpu = 0; cpu < CPUS_PER_SOCKET; cpu++) {
for (event = 0; event < N_HTMMEVENTS; event++) {
if (get_pebs_event(event) == N_HTMMEVENTS) { //这里是在枚举有多少个要收集的数据,根据系统不同有的采样用不到,所以需要将这个指针变为NULL
mem_event[cpu][event] = NULL;
continue;
}
if (__perf_event_open(get_pebs_event(event), 0, cpu, event, pid)) //这一步获得每个perf事件对应的文件描述符
return -1;
if (htmm__perf_event_init(mem_event[cpu][event], BUFFER_SIZE)) //这一步将每个事件和ring buffer对应
return -1;
}
}
return 0;
}这一步就是要创建perf文件描述符,这里重写了一个名为htmm__perf_event_open的perf_event_open,但是核心操作是差不多的。从调用入口来看,传入的参数依次是要采样事件的宏定义,0这里值config2不用,第几个cpu,第几个perf event,进程的pid
/********************/
/*传入要采样事件的宏定义,config1=0,cpu个数,事件个数,pid(为0就监控所有);因为这里是在循环时open,每个cpu都有一个文件操作符在做这件事*/
/*******************/
static int __perf_event_open(__u64 config, __u64 config1, __u64 cpu,
__u64 type, __u32 pid)
{
struct perf_event_attr attr; // 函数需要的结构体,告诉这个文件描述符该怎么创建,因为采样不同的事件最后传回的perf_event结构体也不一样。
struct file *file; // 已打开的文件在内核中用file结构体表示,文件描述符表中的指针指向file结构体。
int event_fd, __pid; // 我们要接收的文件句柄
memset(&attr, 0, sizeof(struct perf_event_attr));
attr.type = PERF_TYPE_RAW; // 要检测的类型有硬件、软件等等咯。This indicates a "raw" implementation-specific event in the config field.
attr.size = sizeof(struct perf_event_attr);
attr.config = config; //要监测的采样事件
/* 但是我们可以发现,这个事件传入的宏定义是作者自己定义的,不是系统有的默认的宏定义。If type is PERF_TYPE_RAW, then a custom "raw" config value is needed. Most CPUs support events that are not covered by the "generalized" events. These are implementation defined; see your CPU manual (for example the Intel Volume 3B documentation or the AMD BIOS and Kernel Developer Guide). The libpfm4 library can be used to translate from the name in the architectural manuals to the raw hex value perf_event_open() expects in this field.*/
attr.config1 = config1; // 这是用作扩展用的
if (config == ALL_STORES)
attr.sample_period = htmm_inst_sample_period; //采样事件间隔
else
attr.sample_period = get_sample_period(0);
attr.sample_type = PERF_SAMPLE_IP | PERF_SAMPLE_TID | PERF_SAMPLE_ADDR; //采样目标IP寄存器、TID实际上是内核(线程)中可调度对象的标识符(当一个进程只有一个线程时,pid和tid总是相同的)、地址
attr.disabled = 0; // 初始状态为启用
attr.exclude_kernel = 1; /* don't count kernel */
attr.exclude_hv = 1; /* don't count hypervisor */
attr.exclude_callchain_kernel = 1; /* exclude kernel callchains */
attr.exclude_callchain_user = 1; /* exclude user callchains */
attr.precise_ip = 1; /* skid constraint,默认是2咦 */
attr.enable_on_exec = 1; /* next exec enables */
if (pid == 0)
__pid = -1;
else
__pid = pid;
event_fd = htmm__perf_event_open(&attr, __pid, cpu, -1, 0); //创建文件描述符
//htmm__perf_event_open在\kernel\events\core.c ,A call to perf_event_open() creates a file descriptor that allows measuring performance information. Each file descriptor corresponds to one event that is measured; these can be grouped together to measure multiple events simultaneously.只不过这里的是修改版的,那么两个文件有些什么区别主要添加了什么呢?
if (event_fd <= 0) {
printk("[error htmm__perf_event_open failure] event_fd: %d\n", event_fd);
return -1;
}
// 这里的读句柄的方式和上面计数用到的不一样。判断是不是写入到了文件,然后保留这个文件的private_data成员指针。private_data指针的指向会根据驱动不同而不同,这里可以获得perf_event指针。
file = fget(event_fd);
if (!file) {
printk("invalid file\n");
return -1;
}
mem_event[cpu][type] = fget(event_fd)->private_data;
return 0;
}分析作者自己封装的htmm__perf_event_open函数,到底有什么区别,因为封装前的__NR_perf_event_open这个系统调用才是主角。但是这里作者封装后的代码并没有这个主角。所以笔者尝试对比一下这个系统调用。
int htmm__perf_event_open(struct perf_event_attr *attr_ptr, pid_t pid,
int cpu, int group_fd, unsigned long flags)
{
……
/*err = perf_copy_attr(attr_ptr, &attr);
if (err)
return err;*/
attr = *attr_ptr;
……
}从结果来看,这里只有一个区别,指针赋值方式。重点在于这个函数没有被系统调用了,少了软中断,由原来的内核态切换到用户态执行。但是系统调用不是说拿到用户态就可以的,接着分析一下整个后台线程中其他的操作。发现作者还有添加新的系统调用:
/* CONFIG_HTMM */
asmlinkage long sys_htmm_start(pid_t pid, int node);
asmlinkage long sys_htmm_end(pid_t pid);
/***************/
#else
SYSCALL_DEFINE2(htmm_start,
pid_t, pid, int, node)
{
ksamplingd_init(pid, node);
return 0;
}
SYSCALL_DEFINE1(htmm_end,
pid_t, pid)
{
ksamplingd_exit();
return 0;
}也就是说虽然这里perf采样不是单独被系统调用的,但是整个后台的采样线程的启动都是被系统调用的,都是运行在内核态的。

到目前为止,后台采样线程的文件描述符已经实现了。采样值的读取需要使用mmap()直接在用户空间操作,少一次复制,因为采样有异步性,需要一个环形队列,这是一个共享内存,一个多生产者单消费者(MPSC)队列。环形缓冲区的头是struct perf_event_mmap_page,记录共享环形缓冲区的特点,这个头大小是一个页面大小。
/*
* Structure of the page that can be mapped via mmap
*/
struct perf_event_mmap_page {
__u32 version; /* version number of this structure */
__u32 compat_version; /* lowest version this is compat with */
/*
* Bits needed to read the hw counters in user-space.
*
* u32 seq;
* s64 count;
*
* do {
* seq = pc->lock;
*
* barrier()
* if (pc->index) {
* count = pmc_read(pc->index - 1);
* count += pc->offset;
* } else
* goto regular_read;
*
* barrier();
* } while (pc->lock != seq);
*
* NOTE: for obvious reason this only works on self-monitoring
* processes.
*/
__u32 lock; /* seqlock for synchronization */
__u32 index; /* hardware counter identifier */
__s64 offset; /* add to hardware counter value */
/*
* Control data for the mmap() data buffer.
*
* User-space reading this value should issue an rmb(), on SMP capable
* platforms, after reading this value -- see perf_event_wakeup().
*/
__u32 data_head; /* head in the data section */
};然后来看ring buffer结构体的信息:
#define PERF_RECORD_MISC_KERNEL (1 << 0)
#define PERF_RECORD_MISC_USER (1 << 1)
#define PERF_RECORD_MISC_OVERFLOW (1 << 2)
struct perf_event_header {
__u32 type;
__u16 misc;
__u16 size;
};
enum perf_event_type {
/*
* The MMAP events record the PROT_EXEC mappings so that we can
* correlate userspace IPs to code. They have the following structure:
*
* struct {
* struct perf_event_header header;
*
* u32 pid, tid;
* u64 addr;
* u64 len;
* u64 pgoff;
* char filename[];
* };
*/
PERF_RECORD_MMAP = 1,
PERF_RECORD_MUNMAP = 2,
/*
* struct {
* struct perf_event_header header;
*
* u32 pid, tid;
* char comm[];
* };
*/
PERF_RECORD_COMM = 3,
/*
* When header.misc & PERF_RECORD_MISC_OVERFLOW the event_type field
* will be PERF_RECORD_*
*
* struct {
* struct perf_event_header header;
*
* { u64 ip; } && PERF_RECORD_IP
* { u32 pid, tid; } && PERF_RECORD_TID
* { u64 time; } && PERF_RECORD_TIME
* { u64 addr; } && PERF_RECORD_ADDR
*
* { u64 nr;
* { u64 event, val; } cnt[nr]; } && PERF_RECORD_GROUP
*
* { u16 nr,
* hv,
* kernel,
* user;
* u64 ips[nr]; } && PERF_RECORD_CALLCHAIN
* };
*/
};接下来将文件描述符和ring buffer相关联。
int htmm__perf_event_init(struct perf_event *event, unsigned long nr_pages)
{
struct perf_buffer *rb = NULL;
int ret = 0, flags = 0;
if (event->cpu == -1 && event->attr.inherit)
return -EINVAL;
ret = security_perf_event_read(event);
if (ret)
return ret;
// 采用伙伴系统分配的话得是2的幂次方
if (nr_pages != 0 && !is_power_of_2(nr_pages))
return -EINVAL;
WARN_ON_ONCE(event->ctx->parent_ctx);
// 加上互斥锁,避免被并发访问
mutex_lock(&event->mmap_mutex);
WARN_ON(event->rb);
// 分配一个环形缓冲区
rb = rb_alloc(nr_pages,
event->attr.watermark ? event->attr.wakeup_watermark : 0,
event->cpu, flags);
if (!rb) {
ret = -ENOMEM;
goto unlock;
}
// 这三个是perf子系统自带的函数,用于实现既定的功能
// 将分配的环形缓冲区与 event 结构体关联起来。主要实现是rcu_assign_pointer(event->rb, rb);
ring_buffer_attach(event, rb);
// 用于初始化环形缓冲区的头就是初始化perf_event_mmap_page。
perf_event_init_userpage(event);
// 更新环形缓冲区头的信息,其中包括对性能事件的统计信息的更新。
perf_event_update_userpage(event);
unlock:
if (!ret) {
// 增加 event->mmap_count 的计数。
atomic_inc(&event->mmap_count);
}
// 解锁
mutex_unlock(&event->mmap_mutex);
return ret;
}2. 页面迁移
2.1 什么样的页面才支持迁移
lru上的page,因为上面挂的是user spcace用的pages,都是从buddy分配器migrate type为movable或reclaim的pageblock上分来的。
no-lru但是movable的页面。no-lru的页面通常是为kernel space分配的page,这种页面通常是unmovable的,但是下面这个commit使得驱动中用到的页面也可以支持迁移。但是在驱动实现的过程中需要置位page->mapping中的second bit,并且实现page->mapping->a_ops中的相关方法。(详细介绍看下面的这个commit,重点关注PageMovable()的实现)
2.2 后台迁移线程
初始化每个NUMA节点上的迁移线程
int kmigraterd_init(void)
{
int nid;
for_each_node_state(nid, N_MEMORY)
kmigraterd_run(nid);
return 0;
}这是线程启动的函数模板,这个线程主要做的还是kmigraterd的事情。当kmigraterd线程或其他线程需要等待某个条件时,它们可以将自己加入到等待队列中,并在条件满足时被唤醒。
static void kmigraterd_run(int nid)
{
pg_data_t *pgdat = NODE_DATA(nid);
if (!pgdat || pgdat->kmigraterd)
return;
init_waitqueue_head(&pgdat->kmigraterd_wait); //初始化等待队列头
pgdat->kmigraterd = kthread_run(kmigraterd, pgdat, "kmigraterd%d", nid);
if (IS_ERR(pgdat->kmigraterd)) {
pr_err("Fails to start kmigraterd on node %d\n", nid);
pgdat->kmigraterd = NULL;
}
}由于第一层节点只会使用降级函数,第二层节点只会使用升级的函数,总的迁移策略分情况来调用。
static int kmigraterd(void *p)
{
pg_data_t *pgdat = (pg_data_t *)p;
int nid = pgdat->node_id;
if (htmm_cxl_mode) {
if (nid == 0)
return kmigraterd_demotion(pgdat);
else
return kmigraterd_promotion(pgdat);
}
if (node_is_toptier(nid))
return kmigraterd_demotion(pgdat);
else
return kmigraterd_promotion(pgdat);
}升级和降级函数每次都会判断页面切割、页面冷却等操作,只有最后实际去做降级升级时不同。
static int kmigraterd_promotion(pg_data_t *pgdat)
{
const struct cpumask *cpumask;
if (htmm_cxl_mode)
cpumask = cpumask_of_node(pgdat->node_id);
else
cpumask = cpumask_of_node(pgdat->node_id - 2);
if (!cpumask_empty(cpumask))
set_cpus_allowed_ptr(pgdat->kmigraterd, cpumask);
// cpu掩码的处理是为了使用 set_cpus_allowed_ptr 将 kmigraterd 线程限制在这些 CPU 上
for ( ; ; ) {
struct mem_cgroup_per_node *pn;
struct mem_cgroup *memcg;
LIST_HEAD(split_list);
if (kthread_should_stop())
break;
pn = next_memcg_cand(pgdat);
if (!pn) {
msleep_interruptible(1000);
continue;
}
memcg = pn->memcg;
if (!memcg || !memcg->htmm_enabled) {
spin_lock(&pgdat->kmigraterd_lock);
if (!list_empty_careful(&pn->kmigraterd_list))
list_del(&pn->kmigraterd_list);
spin_unlock(&pgdat->kmigraterd_lock);
continue;
}
/* performs split */
if (htmm_thres_split != 0 &&
!list_empty(&(&pn->deferred_split_queue)->split_queue)) {
unsigned long nr_split;
nr_split = deferred_split_scan_for_htmm(pn, &split_list);
if (!list_empty(&split_list)) {
putback_split_pages(&split_list, mem_cgroup_lruvec(memcg, pgdat));
}
}
if (need_lru_cooling(pn))
cooling_node(pgdat, memcg);
else if (need_lru_adjusting(pn)) {
adjusting_node(pgdat, memcg, true);
if (pn->need_adjusting_all == true)
// adjusting the inactive list
adjusting_node(pgdat, memcg, false);
}
// 以上的操作和降级时是一样的。
/* promotes hot pages to fast memory node */
if (need_lowertier_promotion(pgdat, memcg)) {
promote_node(pgdat, memcg);
}
msleep_interruptible(htmm_promotion_period_in_ms);
}
return 0;
}
static int kmigraterd_demotion(pg_data_t *pgdat)
{
const struct cpumask *cpumask = cpumask_of_node(pgdat->node_id);
if (!cpumask_empty(cpumask))
set_cpus_allowed_ptr(pgdat->kmigraterd, cpumask);
//处理这个节点里的内存控制组
for ( ; ; ) {
struct mem_cgroup_per_node *pn;
struct mem_cgroup *memcg;
unsigned long nr_exceeded = 0;
LIST_HEAD(split_list);
if (kthread_should_stop())
break;
pn = next_memcg_cand(pgdat); //获取下一个要处理的内存控制组(memcg)
// 如果没有获取到 memcg,表示没有可处理的 memcg,进入睡眠状态并等待 1000 毫秒(1秒)
if (!pn) {
msleep_interruptible(1000);
continue;
}
memcg = pn->memcg;
//如果没拿到内存控制组或者没开启htmm
if (!memcg || !memcg->htmm_enabled) {
spin_lock(&pgdat->kmigraterd_lock);
if (!list_empty_careful(&pn->kmigraterd_list))
list_del(&pn->kmigraterd_list); //从 kmigraterd_list 中移除当前 memcg
spin_unlock(&pgdat->kmigraterd_lock);
continue;
}
/* performs split */
//是否需要执行 split 操作。如果有需要,执行 deferred_split_scan_for_htmm 函数进行 split,并将分裂的页面放回到 memcg 的 LRU 列表中
if (htmm_thres_split != 0 &&
!list_empty(&(&pn->deferred_split_queue)->split_queue)) {
unsigned long nr_split;
nr_split = deferred_split_scan_for_htmm(pn, &split_list);
if (!list_empty(&split_list)) {
putback_split_pages(&split_list, mem_cgroup_lruvec(memcg, pgdat));
}
}
/* performs cooling */
//检查是否需要 LRU cooling(页面冷却)
if (need_lru_cooling(pn))
cooling_node(pgdat, memcg);
else if (need_lru_adjusting(pn)) {
//检查是否需要 LRU adjusting(页面调整)。如果需要,执行 adjusting_node 函数,可能包括调整活动列表和非活动列表。
adjusting_node(pgdat, memcg, true);
if (pn->need_adjusting_all == true)
// adjusting the inactive list
adjusting_node(pgdat, memcg, false);
}
/* demotes inactive lru pages */
//检查是否需要对顶层节点进行降级操作
if (need_toptier_demotion(pgdat, memcg, &nr_exceeded)) {
demote_node(pgdat, memcg, nr_exceeded);
}
//if (need_direct_demotion(pgdat, memcg))
// goto demotion;
/* default: wait 50 ms */
//通过 wait_event_interruptible_timeout 函数等待条件变为真,条件是需要直接降级(need_direct_demotion 返回真)。如果超时或者收到信号,则继续下一轮循环。
wait_event_interruptible_timeout(pgdat->kmigraterd_wait,
need_direct_demotion(pgdat, memcg),
msecs_to_jiffies(htmm_demotion_period_in_ms));
}
return 0;
}2.3 页面升级
mem_cgroup在每个node下,都有一个lruvec, 这个lruvec保存在mem_cgroup_per_node结构中。准确的说是如果没有开启memcg,则lru等于node上的lru,每个node就活跃/不活跃链表各一个。
在正式升级操作之前,升级函数调用一个获得页面数的函数,确认要升级去的节点还有多少空间用于接收。
static bool promotion_available(int target_nid, struct mem_cgroup *memcg,
unsigned long *nr_to_promote)
{
pg_data_t *pgdat;
unsigned long max_nr_pages, cur_nr_pages;
unsigned long nr_isolated;
unsigned long fasttier_max_watermark;
if (target_nid == NUMA_NO_NODE)
return false;
pgdat = NODE_DATA(target_nid);
cur_nr_pages = get_nr_lru_pages_node(memcg, pgdat); // 当前 memcg 在目标节点上的 LRU 页面数量 cur_nr_pages
max_nr_pages = memcg->nodeinfo[target_nid]->max_nr_base_pages; // 该 memcg 在目标节点上的最大页面数量 max_nr_pages
nr_isolated = node_page_state(pgdat, NR_ISOLATED_ANON) +
node_page_state(pgdat, NR_ISOLATED_FILE); // 计算目标节点上被隔离的页面数量 nr_isolated,包括被隔离的匿名页和文件页
fasttier_max_watermark = get_memcg_promotion_watermark(max_nr_pages); // 用于快速内存节点的最大水印,水印的保留量
if (max_nr_pages == ULONG_MAX) { //表示 memcg 没有限制,直接将 nr_to_promote 设置为目标节点的空闲页面数量
*nr_to_promote = node_free_pages(pgdat);
return true;
} //快速层还有多少空间就迁移多少
else if (cur_nr_pages + nr_isolated < max_nr_pages - fasttier_max_watermark) {
*nr_to_promote = max_nr_pages - fasttier_max_watermark - cur_nr_pages - nr_isolated;
return true;
}
return false;
}
static unsigned long promote_node(pg_data_t *pgdat, struct mem_cgroup *memcg)
{
struct lruvec *lruvec = mem_cgroup_lruvec(memcg, pgdat); // 获取当前 memcg 在给定 pgdat 上的 lruvec
unsigned long nr_to_promote, nr_promoted = 0, tmp; // 要升级的页面数量
enum lru_list lru = LRU_ACTIVE_ANON; // LRU列表类型
short priority = DEF_PRIORITY; // 升级的优先级
int target_nid = htmm_cxl_mode ? 0 : next_promotion_node(pgdat->node_id); // 升级要去的目标节点
//检查是否有足够的页面可供升级,并获取实际要升级的页面数量 nr_to_promote
if (!promotion_available(target_nid, memcg, &nr_to_promote))
return 0;
//确保 nr_to_promote 不超过当前 lruvec 中的最大页面数量
nr_to_promote = min(nr_to_promote,
lruvec_lru_size(lruvec, lru, MAX_NR_ZONES));
// 如果不迁移或者没有要迁移的,这个判断是做什么的?
if (nr_to_promote == 0 && htmm_mode == HTMM_NO_MIG) {
lru = LRU_INACTIVE_ANON;
nr_to_promote = min(tmp, lruvec_lru_size(lruvec, lru, MAX_NR_ZONES));
}
do {
// 调用 promote_lruvec 函数,将指定数量的页面从当前节点的 LRU 列表升级到目标节点
// 当升级的页面数量够了,或者优先级比0小就不迁移了。priority从某个数开始,每次扫描不到要求的 page 就会递减,priority = 0 代表扫描整个 list 都迁移不到要求的数量
nr_promoted += promote_lruvec(nr_to_promote, priority, pgdat, lruvec, lru);
if (nr_promoted >= nr_to_promote)
break;
priority--;
} while (priority);
return nr_promoted;
}
//每个批次的迁移函数
static unsigned long promote_lruvec(unsigned long nr_to_promote, short priority,
pg_data_t *pgdat, struct lruvec *lruvec, enum lru_list lru)
{
unsigned long nr_promoted = 0, nr;
nr = nr_to_promote >> priority; //这次迁移多少具体是由优先级决定
if (nr)
nr_promoted += promote_active_list(nr, lruvec, lru);
return nr_promoted;
}
//这是在分层内存中独有的操作。
static unsigned long promote_active_list(unsigned long nr_to_scan,
struct lruvec *lruvec, enum lru_list lru)
{
LIST_HEAD(page_list);
pg_data_t *pgdat = lruvec_pgdat(lruvec);
unsigned long nr_taken, nr_promoted;
lru_add_drain();
spin_lock_irq(&lruvec->lru_lock);
nr_taken = isolate_lru_pages(nr_to_scan, lruvec, lru, &page_list, 0);
__mod_node_page_state(pgdat, NR_ISOLATED_ANON, nr_taken);
spin_unlock_irq(&lruvec->lru_lock);
if (nr_taken == 0)
return 0;
// 这里接着调用下去参数有一个是page list,最后调用的就是migrate_pages
nr_promoted = promote_page_list(&page_list, pgdat);
spin_lock_irq(&lruvec->lru_lock);
move_pages_to_lru(lruvec, &page_list);
__mod_node_page_state(pgdat, NR_ISOLATED_ANON, -nr_taken);
spin_unlock_irq(&lruvec->lru_lock);
mem_cgroup_uncharge_list(&page_list);
free_unref_page_list(&page_list);
return nr_promoted;
}所以每次被升级的页面数量是根据目前的上层节点空闲容量决定的,而每次被升级的方式是一个list,这些是从memcg在某个node的lru中以priority的方式分批次升级上去的。要看升级和降级页面操作最后是否都聚焦到调用migrate_pages,是的。
2.4 页面降级
static unsigned long demote_node(pg_data_t *pgdat, struct mem_cgroup *memcg,
unsigned long nr_exceeded)
{
struct lruvec *lruvec = mem_cgroup_lruvec(memcg, pgdat);
short priority = DEF_PRIORITY;
unsigned long nr_to_reclaim = 0, nr_evictable_pages = 0, nr_reclaimed = 0;
enum lru_list lru;
bool shrink_active = false;
for_each_evictable_lru(lru) {
if (!is_file_lru(lru) && is_active_lru(lru))
continue;
// 对于非文件 LRU 列表中的活跃页面(is_active_lru 为真),将其数量添加到 nr_evictable_pages
nr_evictable_pages += lruvec_lru_size(lruvec, lru, MAX_NR_ZONES);
}
//!!! 这里有一个传入的参数要回收的页面数量。
nr_to_reclaim = nr_exceeded;
// 如果 nr_exceeded 大于 nr_evictable_pages 且需要直接降级(need_direct_demotion 为真),将 shrink_active 设置为真,表示需要压缩活跃页面。
if (nr_exceeded > nr_evictable_pages && need_direct_demotion(pgdat, memcg))
shrink_active = true;
// 实际的页面降级操作,和页面升级一样,这里也是由优先级和总量是否大于nr_to_reclaim来决定最终nr_reclaimed这个要迁移的数量
do {
nr_reclaimed += demote_lruvec(nr_to_reclaim - nr_reclaimed, priority,
pgdat, lruvec, shrink_active);
if (nr_reclaimed >= nr_to_reclaim)
break;
priority--;
} while (priority);
// 确定要降级的数量之后重新定义温暖页面的阈值
if (htmm_nowarm == 0) {
int target_nid = htmm_cxl_mode ? 1 : next_demotion_node(pgdat->node_id);
unsigned long nr_lowertier_active =
target_nid == NUMA_NO_NODE ? 0: need_lowertier_promotion(NODE_DATA(target_nid), memcg);
// 这个比大小大概是个什么意思???
nr_lowertier_active = nr_lowertier_active < nr_to_reclaim ?
nr_lowertier_active : nr_to_reclaim;
if (nr_lowertier_active && nr_reclaimed < nr_lowertier_active)
memcg->warm_threshold = memcg->active_threshold;
}
/* check the condition 这一段重置是否需要降级的标识符 */
do {
unsigned long max = memcg->nodeinfo[pgdat->node_id]->max_nr_base_pages;
if (get_nr_lru_pages_node(memcg, pgdat) +
get_memcg_demotion_watermark(max) < max)
WRITE_ONCE(memcg->nodeinfo[pgdat->node_id]->need_demotion, false);
} while (0);
return nr_reclaimed;
}
// 页面降级实际操作的函数,之后调用自定义的migrate_page_list,调用内核自带的migrate_pages,完成操作。
static unsigned long demote_lruvec(unsigned long nr_to_reclaim, short priority,
pg_data_t *pgdat, struct lruvec *lruvec, bool shrink_active)
{
enum lru_list lru, tmp;
unsigned long nr_reclaimed = 0;
long nr_to_scan;
/* we need to scan file lrus first */
for_each_evictable_lru(tmp) {
lru = (tmp + 2) % 4;
if (!shrink_active && !is_file_lru(lru) && is_active_lru(lru))
continue;
if (is_file_lru(lru)) {
nr_to_scan = lruvec_lru_size(lruvec, lru, MAX_NR_ZONES);
} else {
nr_to_scan = lruvec_lru_size(lruvec, lru, MAX_NR_ZONES) >> priority;
if (nr_to_scan < nr_to_reclaim)
nr_to_scan = nr_to_reclaim * 11 / 10; // because warm pages are not demoted
}
if (!nr_to_scan)
continue;
// 不太明白为什么每次都是分批在做,可能是防止被锁太久了之类的
while (nr_to_scan > 0) {
unsigned long scan = min(nr_to_scan, SWAP_CLUSTER_MAX);
nr_reclaimed += demote_inactive_list(scan, scan,
lruvec, lru, shrink_active);
nr_to_scan -= (long)scan;
if (nr_reclaimed >= nr_to_reclaim)
break;
}
if (nr_reclaimed >= nr_to_reclaim)
break;
}
return nr_reclaimed;
}
static unsigned long demote_inactive_list(unsigned long nr_to_scan,
unsigned long nr_to_reclaim, struct lruvec *lruvec,
enum lru_list lru, bool shrink_active)
{
LIST_HEAD(page_list);
pg_data_t *pgdat = lruvec_pgdat(lruvec);
unsigned long nr_reclaimed = 0, nr_taken;
int file = is_file_lru(lru);
lru_add_drain();
// 每次迁移前将页面从LRU list中独立出来,避免又被其他操作用了
spin_lock_irq(&lruvec->lru_lock);
nr_taken = isolate_lru_pages(nr_to_scan, lruvec, lru, &page_list, 0);
__mod_node_page_state(pgdat, NR_ISOLATED_ANON + file, nr_taken);
spin_unlock_irq(&lruvec->lru_lock);
if (nr_taken == 0) {
return 0;
}
nr_reclaimed = shrink_page_list(&page_list, pgdat, lruvec_memcg(lruvec),
shrink_active, nr_to_reclaim);
spin_lock_irq(&lruvec->lru_lock);
move_pages_to_lru(lruvec, &page_list);
__mod_node_page_state(pgdat, NR_ISOLATED_ANON + file, -nr_taken);
spin_unlock_irq(&lruvec->lru_lock);
mem_cgroup_uncharge_list(&page_list);
free_unref_page_list(&page_list);
return nr_reclaimed;
}
static unsigned long shrink_page_list(struct list_head *page_list,
pg_data_t* pgdat, struct mem_cgroup *memcg, bool shrink_active,
unsigned long nr_to_reclaim)
{
LIST_HEAD(demote_pages);
LIST_HEAD(ret_pages);
unsigned long nr_reclaimed = 0;
unsigned long nr_demotion_cand = 0;
cond_resched();
while (!list_empty(page_list)) {
struct page *page;
page = lru_to_page(page_list);
list_del(&page->lru);
if (!trylock_page(page))
goto keep; // 使用 trylock_page 尝试获取页面的锁,如果获取不到
if (!shrink_active && PageAnon(page) && PageActive(page))
goto keep_locked; // 如果不允许压缩活跃页面且页面是匿名页面且是活跃的
if (unlikely(!page_evictable(page)))
goto keep_locked; // 如果页面不可被驱逐
if (PageWriteback(page))
goto keep_locked; // 如果页面正在进行写回
if (PageTransHuge(page) && !thp_migration_supported())
goto keep_locked; // 如果页面是透明巨页(PageTransHuge)并且不支持透明巨页迁移
if (!PageAnon(page) && nr_demotion_cand > nr_to_reclaim + HTMM_MIN_FREE_PAGES)
goto keep_locked; // 如果页面是匿名页面并且候选降级的页面数量已经超过了要回收的页面数量加上一个最小的页面数量 HTMM_MIN_FREE_PAGES
if (htmm_nowarm == 0 && PageAnon(page)) { // 如果开启了 htmm_nowarm 并且页面是匿名页面,进一步检查页面是否满足“暖”页面的条件
if (PageTransHuge(page)) { // 如果页面是匿名页面且是透明巨页,进一步检查透明巨页的元数据页面的索引或者普通页面的索引是否超过 memcg 的暖页面阈值
struct page *meta = get_meta_page(page);
if (meta->idx >= memcg->warm_threshold)
goto keep_locked;
} else {
unsigned int idx = get_pginfo_idx(page);
if (idx >= memcg->warm_threshold)
goto keep_locked;
}
}
unlock_page(page);
/* 添加操作将页面虚拟地址输出 */
if(PageTransHuge(page)){
}else{
}
// !!!这一步会把筛选合格的页面放入迁移链表,具体执行迁移操作。
list_add(&page->lru, &demote_pages);
nr_demotion_cand += compound_nr(page);
continue;
keep_locked:
unlock_page(page);
keep:
list_add(&page->lru, &ret_pages);
}
// 对 demote_pages 链表中的页面执行迁移操作,并返回实际回收的页面数量。
nr_reclaimed = migrate_page_list(&demote_pages, pgdat, false);
if (!list_empty(&demote_pages))
list_splice(&demote_pages, page_list);
list_splice(&ret_pages, page_list);
return nr_reclaimed;
}
static unsigned long migrate_page_list(struct list_head *migrate_list,
pg_data_t *pgdat, bool promotion)
{
int target_nid;
unsigned int nr_succeeded = 0;
if (promotion)
target_nid = htmm_cxl_mode ? 0 : next_promotion_node(pgdat->node_id);
else
target_nid = htmm_cxl_mode ? 1 : next_demotion_node(pgdat->node_id);
if (list_empty(migrate_list))
return 0;
if (target_nid == NUMA_NO_NODE)
return 0;
migrate_pages(migrate_list, alloc_migrate_page, NULL,
target_nid, MIGRATE_ASYNC, MR_NUMA_MISPLACED, &nr_succeeded);
if (promotion)
count_vm_events(HTMM_NR_PROMOTED, nr_succeeded);
else
count_vm_events(HTMM_NR_DEMOTED, nr_succeeded);
return nr_succeeded;
}2.5 冷却处理
在前面的迁移线程中,有一段是对于页面热度的调整,也就是冷处理。 Memtis 根据采样的内存访问次数执行冷却。冷却时间必须足够长,因为它决定了直方图中反映的采样内存访问总数。
if (need_lru_cooling(pn)) //pn是要处理的内存控制组(memcg)
cooling_node(pgdat, memcg);
else if (need_lru_adjusting(pn)) {
adjusting_node(pgdat, memcg, true);
if (pn->need_adjusting_all == true)
// adjusting the inactive list
adjusting_node(pgdat, memcg, false);
}接下来的分析,都将围绕上面这段代码。首先是need_lru_cooling(pn)
// need_cooling是一个布尔值,在memcontrol.h中定义,每一个cgroup有一个
static bool need_lru_cooling(struct mem_cgroup_per_node *pn)
{
return READ_ONCE(pn->need_cooling); // 这个宏确保所生成的代码对向其传递的参数的值确实只被访问过一次。
}
// 什么时候会修改冷却布尔值呢?
// 这是改变cooling的函数:
static void set_lru_cooling(struct mm_struct *mm)
{
//获得该进程的cgroup
struct mem_cgroup *memcg = get_mem_cgroup_from_mm(mm);
struct mem_cgroup_per_node *pn;
int nid;
if (!memcg || !memcg->htmm_enabled)
return;
//获得每个node的cgroup,如果不为空就将要cooling设置为真
for_each_node_state(nid, N_MEMORY) {
pn = memcg->nodeinfo[nid];
if (!pn)
continue;
WRITE_ONCE(pn->need_cooling, true);
}
}
//这是唯一调用set_lru_cooling的函数,而且set_lru_cooling也是唯一将need_cooling设置为true的函数
//但是首先看看memtis对cgroup memory部分有哪些修改,这个结构体是在\include\linux\memcontrol.h struct mem_cgroup新增如下:
#ifdef CONFIG_HTMM /* struct mem_cgroup */
bool htmm_enabled;
unsigned long max_nr_dram_pages; /* DRAM最大可以接受的页面数 */
unsigned long nr_active_pages; /* 由need_lru_cooling()更新的活跃页面数 */
/* stat for sampled accesses */
unsigned long nr_sampled; /* 总的被采样到的访问数 */
unsigned long nr_sampled_for_split; /* 总的被采样到的,被拆分的页面数 */
unsigned long nr_dram_sampled; /* 采样到的访问dram的: n(i) */
unsigned long prev_dram_sampled; /* 上一轮采样到的访问dram的 n(i-1)? */
unsigned long max_dram_sampled; /* 对dram的访问 (estimated) */
unsigned long prev_max_dram_sampled; /* 对dram的访问 (estimated) */
unsigned long nr_max_sampled; /* 访问DRAM和NVM的校准次数 */
/* thresholds */
unsigned int active_threshold; /* hot */
unsigned int warm_threshold;
unsigned int bp_active_threshold; /* 期望的阈值? */
/* split */
unsigned int split_threshold;
unsigned int split_active_threshold;
unsigned int nr_split;
unsigned int nr_split_tail_idx;
/* 用于计算平均采样大页avg_samples_hp? 具体在check_transhuge_cooling()中使用 */
unsigned int sum_util;
unsigned int num_util;
/* */
unsigned long access_map[21];
/* 直方图。指数范围 */
/* "hotness_map" 决定热阈值用的.
* "ebp_hotness_map" 是用来准确判断的
* 当系统只使用4KB(基本)页时预期的DRAM命中率.
*/
unsigned long hotness_hg[16]; // 页面访问直方图
unsigned long ebp_hotness_hg[16]; // 期望的 bage 页面 ???
/* 锁住直方图的 */
spinlock_t access_lock;
/* etc */
bool cooled;
bool split_happen;
bool need_split;
unsigned int cooling_clock; // 不知道这个锁是干啥的虽然和冷处理有关
unsigned long nr_alloc; // 在冷处理也有用,不过仍然不知道是干啥用的
#endif /* CONFIG_HTMM */
#ifdef CONFIG_HTMM /* struct mem_cgroup_per_node这个结构体是包含在struct mem_cgroup中的 */
unsigned long max_nr_base_pages; /* Set by "max_at_node" param */
struct list_head kmigraterd_list;
bool need_cooling;
bool need_adjusting;
bool need_adjusting_all;
bool need_demotion;
struct deferred_split deferred_split_queue;
struct list_head deferred_list;
#endif
static bool __cooling(struct mm_struct *mm,
struct mem_cgroup *memcg)
{
int nid;
/* check whether the previous cooling is done or not. */
for_each_node_state(nid, N_MEMORY) {
struct mem_cgroup_per_node *pn = memcg->nodeinfo[nid];
if (pn && READ_ONCE(pn->need_cooling)) {
//不为空且目前是需要cooling的
spin_lock(&memcg->access_lock); // 锁直方图数据的
memcg->cooling_clock++;
spin_unlock(&memcg->access_lock);
return false;
}
}
spin_lock(&memcg->access_lock);
// 由访问锁保护,将memcg->hotness_hg[i]、memcg->ebp_hotness_hg[i]、memcg->access_map[i](这个是每个cpu的记录的应该)、memcg->sum_util、memcg->num_util这些都被定义为0. 但是吧,这是吧直方图都清空了的意思吗?这不是cooling啊,emmmm
reset_memcg_stat(memcg);
memcg->cooling_clock++;
memcg->bp_active_threshold--; // 是期望阈值,冷处理的话相应减1
memcg->cooled = true;
smp_mb();
spin_unlock(&memcg->access_lock);
set_lru_cooling(mm);
return true;
}
/*在htmm_core文件中,函数update_pginfo有关于如何决定冷处理和做冷处理的调用片段*/
/* cooling and split decision nr_sampled是被采样到的总访问数htmm_cooling_period是200万*/
if (memcg->nr_sampled % htmm_cooling_period == 0 || //很显然这位兄弟也清除,余数怎么合适刚好是0呢?!
need_memcg_cooling(memcg)) {
/* cooling -- updates thresholds and sets need_cooling flags */
if (__cooling(mm, memcg)) {
……}
}
// Memtis 每 200 万条记录执行一次冷却,考虑到千兆字节级快速层内存大小,这已经足够大了。
// 补充的另一个要cooling的方法
static bool need_memcg_cooling (struct mem_cgroup *memcg)
{
unsigned long usage = page_counter_read(&memcg->memory); // 这个内存控制组里已经使用了的内存量
if (memcg->nr_alloc + htmm_thres_cooling_alloc <= usage) {
memcg->nr_alloc = usage;
return true;
}
return false;
}看到这里发现和论文里描述的不太一样啊,兄弟,这个决定是否要冷却页面的参数的布尔值变化咋这么奇怪呢?🤨😑🙄mem_group里面添加的那些新的参数不太懂是干啥的呀。
接下来看看具体冷处理的实现,总的来说,应该会有他论文里所说的:kmigerated 扫描页面列表并将每个页面的访问计数减半。对于大页面,kmigrated 还会对每个子页面的元数据进行冷却。如果页面具有最高的 bin 索引(即 𝐵𝑖 = 𝑚𝑎𝑥),则 𝐵𝑖 在冷却后可能不会改变,因此 Memtis 检查冷却页面的 bin 索引并在必要时更正直方图。
static void cooling_node(pg_data_t *pgdat, struct mem_cgroup *memcg)
{
unsigned long nr_to_scan, nr_scanned = 0, nr_max_scan = 12; // 最大扫描次数12次
struct lruvec *lruvec = mem_cgroup_lruvec(memcg, pgdat); // NUMA节点+内存控制组=对应LRU
struct mem_cgroup_per_node *pn = memcg->nodeinfo[pgdat->node_id];
enum lru_list lru = LRU_ACTIVE_ANON;
re_cooling:
nr_to_scan = lruvec_lru_size(lruvec, lru, MAX_NR_ZONES); // LRU大小,有多少需要扫描的页
do {
unsigned long scan = nr_to_scan >> 3; /* 除以8,这类操作都是限制扫描的数量,然后减少锁的时间12.5% */
if (!scan)
scan = nr_to_scan;
/* limits the num. of scanned pages to reduce the lock holding time */
nr_scanned += cooling_active_list(scan, lruvec, lru); // 实际执行降温操作的
nr_max_scan--;
} while (nr_scanned < nr_to_scan && nr_max_scan);
if (is_active_lru(lru)) { // 将active链表降温后,又降温inactive的
lru = LRU_INACTIVE_ANON;
nr_max_scan = 12;
nr_scanned = 0;
goto re_cooling;
}
/* active file list 前面是扫描匿名页,现在扫描文件页,但是只扫描活跃文件页,为啥不活跃文件页不冷处理呢??*/
cooling_active_list(lruvec_lru_size(lruvec, LRU_ACTIVE_FILE, MAX_NR_ZONES),
lruvec, LRU_ACTIVE_FILE);
//if (nr_scanned >= nr_to_scan)
WRITE_ONCE(pn->need_cooling, false);
}
static unsigned long cooling_active_list(unsigned long nr_to_scan,
struct lruvec *lruvec, enum lru_list lru)
{
unsigned long nr_taken;
struct mem_cgroup *memcg = lruvec_memcg(lruvec);
pg_data_t *pgdat = lruvec_pgdat(lruvec);
LIST_HEAD(l_hold); // 新定义了3个LRU list
LIST_HEAD(l_active);
LIST_HEAD(l_inactive);
int file = is_file_lru(lru);
lru_add_drain(); // 确保活跃列表的 lru 添加操作处于稳定状态?
spin_lock_irq(&lruvec->lru_lock);
nr_taken = isolate_lru_pages(nr_to_scan, lruvec, lru, &l_hold, 0); // 将这些页面独立出来,放入l_hold
__mod_node_page_state(pgdat, NR_ISOLATED_ANON + file, nr_taken); // 主要是页面脏页之类的状态修改
spin_unlock_irq(&lruvec->lru_lock);
cond_resched();
while (!list_empty(&l_hold)) {
//将刚刚独立出来的每个页面都分析一下
struct page *page;
page = lru_to_page(&l_hold);
list_del(&page->lru);
if (unlikely(!page_evictable(page))) {
putback_lru_page(page);
continue;
}
if (!file) { // 如果是匿名页
int still_hot;
if (PageTransHuge(compound_head(page))) {
struct page *meta = get_meta_page(page); // 等等,这个就是文章说的hot meta?
// 这个只是对于大页面来说
#ifdef DEFERRED_SPLIT_ISOLATED
// 这一段是和页面拆分有关的
if (check_split_huge_page(memcg, get_meta_page(page), false)) {
spin_lock_irq(&lruvec->lru_lock);
if (deferred_split_huge_page_for_htmm(compound_head(page))) {
spin_unlock_irq(&lruvec->lru_lock);
check_transhuge_cooling((void *)memcg, page, false);
continue;
}
spin_unlock_irq(&lruvec->lru_lock);
}
#endif
check_transhuge_cooling((void *)memcg, page, false);
if (meta->idx >= memcg->active_threshold)
still_hot = 2;
else
still_hot = 1;
}
else { // 大页面降温和小页面降温还不一样,大页面降温有个对于元数据的修改,小页面降温就不太一样。
still_hot = cooling_page(page, lruvec_memcg(lruvec));
}
// 判断完页面之后要将页面放回lru,这个时候需要判断放active还是inactive的lru
// still_hot这个参数又是具体由降温函数完成操作后的返回
if (still_hot == 2) {
/* page is still hot after cooling */
if (!PageActive(page))
SetPageActive(page);
list_add(&page->lru, &l_active);
continue;
}
else if (still_hot == 0) {
/* not cooled page */
if (PageActive(page))
list_add(&page->lru, &l_active);
else
list_add(&page->lru, &l_inactive);
continue;
}
// still_hot == 1
}
/* cold or file page */
ClearPageActive(page);
SetPageWorkingset(page);
list_add(&page->lru, &l_inactive);
}
//上一步将所有独立出来的页面降温并且分类放好了在一个临时的active和inactive list
//现在是放回lru
spin_lock_irq(&lruvec->lru_lock);
move_pages_to_lru(lruvec, &l_active);
move_pages_to_lru(lruvec, &l_inactive);
list_splice(&l_inactive, &l_active);
__mod_node_page_state(pgdat, NR_ISOLATED_ANON + file, -nr_taken);
spin_unlock_irq(&lruvec->lru_lock);
mem_cgroup_uncharge_list(&l_active);
free_unref_page_list(&l_active);
return nr_taken;
}上面这个函数主要是加锁,对于单个页面开始判断做冷处理操作。并且降温处理后,将他们放入不同的活跃/不活跃链表。但是具体冷处理操作改变的是哪里的值,又是怎么和bins的数量相关联的?先看小页面的页面cooling:
int cooling_page(struct page *page, struct mem_cgroup *memcg)
{
struct htmm_cooling_arg hca = {
.page_is_hot = 0,
.memcg = memcg,
};
// 这个结构体在反向映射中使用非常多
struct rmap_walk_control rwc = {
.rmap_one = cooling_page_one,
.arg = (void *)&hca,
};
if (!memcg || !memcg->htmm_enabled)
return false;
if (!PageAnon(page) || PageKsm(page))
return false;
if (!page_mapped(page))
return false;
rmap_walk(page, &rwc); // 做主要操作的还是这句话
return hca.page_is_hot;
}
static bool cooling_page_one(struct page *page, struct vm_area_struct *vma,
unsigned long address, void *arg)
{
struct htmm_cooling_arg *hca = arg;
struct page_vma_mapped_walk pvmw = {
.page = page,
.vma = vma,
.address = address,
};
pginfo_t *pginfo;
while (page_vma_mapped_walk(&pvmw)) {
address = pvmw.address;
page = pvmw.page;
if (pvmw.pte) {
struct page *pte_page;
unsigned long prev_accessed, cur_idx;
unsigned int memcg_cclock;
pte_t *pte = pvmw.pte;
pte_page = virt_to_page((unsigned long)pte);
if (!PageHtmm(pte_page))
continue;
pginfo = get_pginfo_from_pte(pte);
if (!pginfo)
continue;
spin_lock(&hca->memcg->access_lock);
memcg_cclock = READ_ONCE(hca->memcg->cooling_clock);
if (memcg_cclock > pginfo->cooling_clock) {
unsigned int diff = memcg_cclock - pginfo->cooling_clock;
int j;
prev_accessed = pginfo->total_accesses;
pginfo->nr_accesses = 0;
for (j = 0; j < diff; j++)
pginfo->total_accesses >>= 1;
cur_idx = get_idx(pginfo->total_accesses);
hca->memcg->hotness_hg[cur_idx]++;
hca->memcg->ebp_hotness_hg[cur_idx]++;
if (cur_idx >= (hca->memcg->active_threshold - 1))
hca->page_is_hot = 2;
else
hca->page_is_hot = 1;
if (get_idx(prev_accessed) >= (hca->memcg->bp_active_threshold))
pginfo->may_hot = true;
else
pginfo->may_hot = false;
pginfo->cooling_clock = memcg_cclock;
}
spin_unlock(&hca->memcg->access_lock);
} else if (pvmw.pmd) {
/* do nothing */
continue;
}
}
return true;
}然后看大页面的页面降温:
struct page *get_meta_page(struct page *page)
{
page = compound_head(page);
return &page[3];
}
void check_transhuge_cooling(void *arg, struct page *page, bool locked)
{
struct mem_cgroup *memcg = arg ? (struct mem_cgroup *)arg : page_memcg(page);
struct page *meta_page;
pginfo_t *pginfo;
int i, idx, offset;
unsigned int memcg_cclock;
if (!memcg || !memcg->htmm_enabled)
return;
meta_page = get_meta_page(page);
spin_lock(&memcg->access_lock);
/* check cooling */
memcg_cclock = READ_ONCE(memcg->cooling_clock);
if (memcg_cclock > meta_page->cooling_clock) {
unsigned int diff = memcg_cclock - meta_page->cooling_clock;
unsigned long prev_idx, cur_idx, skewness = 0;
unsigned int refs = 0;
unsigned int bp_hot_thres = min(memcg->active_threshold,
memcg->bp_active_threshold);
/* perform cooling */
meta_page->hot_utils = 0;
for (i = 0; i < HPAGE_PMD_NR; i++) { // subpages
int j;
idx = 4 + i / 4;
offset = i % 4;
pginfo =&(page[idx].compound_pginfo[offset]);
prev_idx = get_idx(pginfo->total_accesses);
if (prev_idx >= bp_hot_thres) {
meta_page->hot_utils++;
refs += pginfo->total_accesses;
}
/* get the sum of the square of H_ij*/
skewness += (pginfo->total_accesses * pginfo->total_accesses);
if (prev_idx >= (memcg->bp_active_threshold))
pginfo->may_hot = true;
else
pginfo->may_hot = false;
/* halves access counts of subpages */
for (j = 0; j < diff; j++)
pginfo->total_accesses >>= 1;
/* updates estimated base page histogram */
cur_idx = get_idx(pginfo->total_accesses);
memcg->ebp_hotness_hg[cur_idx]++;
}
/* halves access count for a huge page */
for (i = 0; i < diff; i++)
meta_page->total_accesses >>= 1;
cur_idx = meta_page->total_accesses;
cur_idx = get_idx(cur_idx);
memcg->hotness_hg[cur_idx] += HPAGE_PMD_NR;
meta_page->idx = cur_idx;
/* updates skewness */
if (meta_page->hot_utils == 0)
skewness = 0;
else if (meta_page->idx >= 13) // very hot pages
skewness = 0;
else {
skewness /= 11; /* scale down */
skewness = skewness / (meta_page->hot_utils);
skewness = skewness / (meta_page->hot_utils);
skewness = get_skew_idx(skewness);
}
meta_page->skewness_idx = skewness;
memcg->access_map[skewness] += 1;
if (meta_page->hot_utils) {
refs /= HPAGE_PMD_NR; /* actual access counts */
memcg->sum_util += refs; /* total accesses to huge pages */
memcg->num_util += 1; /* the number of huge pages */
}
meta_page->cooling_clock = memcg_cclock;
} else
meta_page->cooling_clock = memcg_cclock;
spin_unlock(&memcg->access_lock);
}采样数据是怎么处理的
线程如果在第二层是升级的函数,在第一层是降级的函数。线程是定时被唤醒开始判断是①迁移数量;②是否要冷却页面;③是否要做页面拆分。每次被升级的页面数量是根据目前的上层节点空闲容量决定的,降级的页面数是有什么决定的?页面冷却是
采样得到的页面要升级是怎么被组织到LRU中去的?
anyway还有一些错误,未完待续

