1.1. 介绍
内核控制组cgroups是一项内核功能,允许为进程分配和限制硬件和系统资源。
创建:在使用systemd(systemd是System Management Daemon的简写(在UNIX系统中,后台进程都按照惯例以d结尾,因此当你看到一个进程的名字以d结尾,那它极有可能是一个后台进程),它是Linux系统中启动的第一个进程)的操作系统中,/sys/fs/cgroup目录都是由systemd在系统启动的过程中挂载的,并且挂载为只读的类型(创建cgroup除了使用cgroup的工具的命令以外,还可以直接在目录里创建相应memory或者cpu的目录,之后默认的cgroup文件会在里面自动生成,但是有的情况下这样的方式创建是不被允许不能成功的即使是sudo)。
结构:每个进程都分配有一个管理cgroup。cgroup以分层树结构排序。可以为单个进程或层次结构的整个分支设置资源限制。使用cgroups将所有进程组织成组,这称为切片slice,slice是一棵树或者一棵子树。scope和service是slice中的一个节点,scope是以资源管理为目的的比如我有一组不太相关但是都需要被限制CPU使用的进程;service是一组相关的进程一起工作,形成一个服务单元。默认情况下, systemd会自动创建slice, scope和service单位的层级,来为cgroup树提供统一结构。
记账:记账(Accounting)功能是指cgroups可以跟踪和记录组内任务(进程或线程)使用资源的情况。收集有关特定进程组(cgroup)使用的CPU时间、内存占用、磁盘I/O等方面的信息。这有助于识别资源密集型任务,管理系统负载,并进行资源分配和优化。记账具有相对较小但非零的开销,其影响取决于工作负载。请注意,打开一个单元的记账也会隐式地为直接包含在同一切片中的所有单元及其所有父切片和单元打开记账。直接包含在其中,因此会计成本不属于单个单位。
内核配置:每个控制组子系统都依赖于相关的配置选项。例如,cpuset子系统应通过CONFIG_CPUSETS内核配置选项启用,io子系统应通过CONFIG_BLK_CGROUP内核配置选项启用等。要启用cgroups中的memory子系统,需要在内核配置时将CONFIG_MEMCG选项设置为y. All of these kernel configuration options may be found in the General setup → Control Group support menu.
1.2. diff V1 V2
/usr/src/linux/Documentation/admin-guide/cgroup-v1
/usr/src/linux/Documentation/admin-guide/cgroup-v2.rst.
cgroup v1 主要包括以下几个概念:
- subsystem(子系统):内核模块,具体的资源控制器,可以被关联到cgroup树。不同资源的控制器不同,例如,内存子系统控制内存资源,CPU子系统控制CPU资源。
- cgroup(控制组):资源隔离的最小单位,表示一组进程和cgroup子系统的关联,例如:通过内存子系统限制一组进程的可用内存资源总量。进程可以加入某个cgroup,也可以从一个cgroup迁移到另一个cgroup,同一进程不能同时存在同类型的两个cgroup中。
- hierarchy(层级):由一系列cgroup按照树状结构排列,每个节点都是一个cgroup,子cgroup默认继承父cgroup的参数和配置。系统可以有多个层级(cgroup树),每个层级可以和不同的subsystem关联,每个subsystem只能和一个层级关联,同一进程可以属于多个层级,但在每个层级中只能属于一个cgroup节点。
在cgroup v2中,去掉了层级(hierarchy)的概念,只有一个层级,所有cgroup在该层级中以树形的方式组织,每个cgroup可以管理多种资源。在cgroup v1中,每种资源一个层级。对于bg和adhoc两个cgroup,bg需要限制blkio和memory两种资源,adhoc需要限制memory和pids两种资源。cgroup v1场景的视图如下: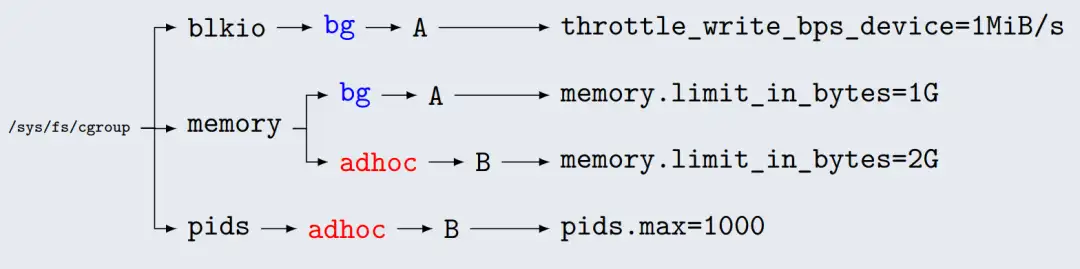
对于cgroup v2,由于所有资源都在同一个cgroup下管理,通过cgroup.sub_controller控制子cgroup启用的controller,这样一来,视图以cgroup为单位,更加清晰和便于管理。
在cgroup v2中,每个cgroup目录下有个名为cgroup.controllers的可读文件,记录了当前cgroup启用的controller。根目录cgroup.controllers文件的内容记录了当前系统支持的所有controller。
在cgroup v2中,每个cgroup目录下有个名为cgroup.controllers的可读文件,记录了当前cgroup启用的controller。根目录下cgroup.controllers文件的内容记录了当前系统支持的所有controller。修改父cgroup的cgroup.subtree_control,增加cgroup controller:
echo "+memory" > test/cgroup.subtree_control
cat test/child/cgroup.controllers
memory删除子cgroup中的controller,也通过修改父cgroup的cgroup.subtree_control实现:
echo "-memory" > test/cgroup.subtree_control
cat test/child/cgroup.controllers当前cgroup中存在进程时,写入不会成功;写入当前cgroup没有启用的controller时,不会成功。
1.3. Unified Control Group Hierarchy
节点存在以下面3种cgroups模式,选择不同模式,会影响到用户空间的 cgroup使用与兼容性:
- legacy:只支持cgroup V1
- hybrid:同时支持cgroup V1和cgroup V2
- unified:只支持cgroup V2又叫Unified Control Group Hierarchy
判断目前是哪种模式参考:
[ $(stat -fc %T /sys/fs/cgroup/) = "cgroup2fs" ] && echo "unified" || ( [ -e \
/sys/fs/cgroup/unified/ ] && echo "hybrid" || echo "legacy")使用unified模式(注意cgroup_no_v1=all):
GRUB_CMDLINE_LINUX="cgroup_enable=memory \
systemd.unified_cgroup_hierarchy=1 \
systemd.legacy_systemd_cgroup_controller=0 cgroup_no_v1=all"使用 legacy 模式:
GRUB_CMDLINE_LINUX="cgroup_enable=memory \
systemd.unified_cgroup_hierarchy=0 \
systemd.legacy_systemd_cgroup_controller=1"使用 hybrid 模式:
GRUB_CMDLINE_LINUX="cgroup_enable=memory \
systemd.unified_cgroup_hierarchy=1 \
systemd.legacy_systemd_cgroup_controller=1"主要是开启GRUB_CMDLINE_LINUX= “systemd.unified_cgroup_hierarchy=yes”才能使用V2版本,有时候内核可能没有默认。
以及貌似在内核编译时也有选项:
# Only unified hierarchy is supported
CONFIG_CGROUP_UNIFIED_SYSTEMD=y2.1.创建一个有内存限制的cgroup
为了创建、管理和监控cgroup,我们需要另一个名为cgroup-tools的包sudo apt install cgroup-tools
创建内存类型的cgroup命名为memhog-limitersudo cgcreate -g memory:memhog-limiter实际操作是创建了一个目录。ls -la /sys/fs/cgroup/memhog-limiter/

设置内存限制,这里有新版的cgroup的软限制是memory.high,硬限制是menory.maxsudo cgset -r memory.max=50M memhog-limiter设置完成后可以输出查看cat /sys/fs/cgroup/memhog-limiter/memory.max

2.2. 去限制内存
memhog:用于测试系统内存管理的工具,它通常用于在Linux系统上进行内存压力测试。它的主要作用是 通过分配大量的内存来模拟内存压力。
创建一个吃内存的脚本
#!/bin/bash
while true; do memhog 100M; id=$(pgrep memhog) ; echo "$id" ; sleep 20; done运行脚本sudo cgexec -g memory:memhog-limiter ./memhog.sh查看这个内存控制组里的pidcat /sys/fs/cgroup/memhog-limiter/cgroup.procs

显然没有控制住,emmmm到底什么原因?后来发现还是得在grub设置systemd.unified_cgroup_hierarchy=1才行。
2.3. 创建namespace
sudo cgexec -g memory:memhog-limiter unshare -fp --mount-proc
To verify that you are in a new namespaceps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 08:00 pts/0 00:00:00 -bash
root 12 1 0 08:00 pts/0 00:00:00 ps -ef新命名空间中,只有bash作为PID 1运行。因此,现在启动的每个服务都将在这个cgroup上下文中启动。
./memhog.sh应该也是被之前那样限制住的情况。
这是facebook关于cgroup2的文档,他们的创建方式不太一样,也可以试试
2.4. namespace又是什么?
Kernel space - 在某个特定namespace内,操作系统内核执行的内存区域。
User space - 在某个特定namespace内,用户模式程序执行的内存区域。
Namespace的类型有:
PID namespace - 进程ID的隔离Namespace
Network namespace - 网络设备和协议栈的隔离Namespace
Mount namespace - 文件系统挂载点的隔离Namespace
IPC namespace - 进程间通信的隔离Namespace
UTS namespace - 主机名和域名的隔离Namespace
User namespace - 用户和用户组的隔离Namespace
通过namespace技术,内核可以为不同的用户空间提供隔离的系统资源,增强安全性和容器化。所以在讨论用户空间和内核空间时,需要明确是在哪个namespace环境下。比如docker容器内的用户空间和内核空间就与宿主机隔离开来。
命名空间是Linux内核用来隔离内核资源的方式。让一些进程只能看到和自己相关的一部分资源。两组感觉不到对方存在。
更多实验参考

